
An application built with the hybrid model of parallel programming can run on a computer cluster using both OpenMP and message passing interface.
Modern embedded applications are becoming complex and demanding with respect to code reuse, as platforms and applications are being developed and implemented rapidly. Implementation is a combination of hardware and software, and may change several times during a product’s lifetime. Hence, efficient hardware alone is not enough. It needs the support of programming models and tools.
Modern field-programmable gate array (FPGA) devices are flexible, and can include up to tens of soft-core processors and IP blocks. The primary objective is a practical solution that is immediately usable in embedded product development.
An application program interface (API) is an abstraction that describes an interface for interaction between system components. In practice, it is a set of functions in a program, such as send_data() or connect_channel(). A common interface is needed to develop complex portable applications efficiently. The same functions must be available to programmers, regardless of API implementation, such as a PC running Linux and NIOS without an operating system (OS).
Consequently, most development and functional verification can be carried out on a workstation. And porting the tested software into target multi-processor system on chip (SoC) should go smoothly. However, some APIs make certain assumptions from the hardware platform, like utilisation of shared memory.

Overall functionality is specified for model-based techniques, and mapped to physical implementation consisting of various processors and fixed-function hardware IP blocks. In addition, efficient software platform services like OSes, drivers and compatibility layers are needed to implement an interface layer that provides suitable abstraction for both software and hardware blocks. These should also offer feasible performance, small memory and area requirements, fast code porting and re-mapping of application tasks.
Application tasks are implemented in processor programs and fixed-function hardware blocks using unified interface layer abstraction. Intel Atom, customisable TTA processors and Altera NIOS are a few examples.
Multi-core communications API (MCAPI) is targeted at inter-core communication, whereas multi-processor API (MPI) and sockets are developed for inter-computer communication. Thus, a principal design goal of MCAPI is to specify a low-latency API to enable efficient use of a network-on-chip. MCAPI’s communication latencies and memory footprint are expected to be significantly lower than MPI’s or sockets’, at the expense of less flexibility.

MCAPIs also enable building of plug-and-play component software environment, development of portable, object-oriented, interoperable code, which is hardware-, OS-, network- and programming-language-independent.
For a system with multiple processor sub-systems, the following architecture decisions must be considered:
- Inter-processor communication
- Partitioning/sharing peripherals (locking required)
- Bandwidth and latency requirements
- May have inherited processor sub-system from another development team or third party
- Risk mitigation by reducing change, fulfilling latency and bandwidth requirements
- Real-time considerations
- If main processor is not real-time enabled, a real-time processor sub-system design partition/sandboxing can be added
- Break the system into smaller sub-systems to service tasks
- Smaller tasks to be designed easily
- Leverage software resources; sometimes a problem is resolved in less time by processor/software rather than hardware design, sequencers or state-machines
- Huge number of processor sub-systems can be implemented; bandwidth and latency can be tailored
- Address real-time aspects of system solution
- FPGA logic has flexible interconnect
- Trade data width with clock frequency using latency experimentation
- Allow experimentation with regards to changing microprocessor sub-system hardware designs; Altera FPGA under-the-hood
- Generic Linux interfaces are used; can be applied in any Linux system

Application portability is often provided by a compatibility layer API. However, traditional multi-computer APIs are too heavy and lack support for extreme heterogeneity like treating hardware IP blocks such as processors, where inter-core communication is expected to be faster and more reliable than inter-computer. Thus, MCAPI aims to be lightweight and efficient than other parallel computing APIs.
General code structure
include <omp.h>
main () {
int var1, var2, var3;
// Serial code
// Beginning of parallel section.
// Specify variable scoping
#pragma omp parallel private(var1, var2)
shared(var3) {
// Parallel section executed by all threads
// All threads join master thread and
disband
}
Resume serial code
}
omp keyword distinguishes pragma as OpenMP pragma and is processed by OpenMP compilers.
Parallel region
#include <omp.h>
main () {
int nthreads, tid;
/* Fork a team of threads
#pragma omp parallel private(tid) {
tid = omp_get_thread_num(); /* Obtain
thread id */
printf(“Hello World from thread = %d\n”,
tid);
if (tid == 0) { /* Only master thread does
this */
nthreads = omp_get_num_threads();
printf(“Number of threads = %d\n”,
nthreads);
}
} /* All threads join master thread and
terminate */
}
Directive
include <omp.h>
#define CHUNKSIZE 10
#define N 100
main () {
int i, chunk;
float a[N], b[N], c[N];
for (i=0; i < N; i++)
a[i] = b[i] = i * 1.0;
chunk = CHUNKSIZE;
#pragma omp parallel shared(a,b,c,chunk)
private(i) {
#pragma omp for schedule(dynamic,chunk)
nowait
for (i=0; i < N; i++)
c[i] = a[i] + b[i];
} /* end of parallel section */
Sections directive
include <omp.h>
#define N 1000
main () {
int i;
float a[N], b[N], c[N], d[N];
for (i=0; i < N; i++) {
a[i] = i * 1.5; b[i] = i + 22.35;
}
#pragma omp parallel shared(a,b,c,d)
private(i) {
#pragma omp sections nowait {
#pragma omp section
for (i=0; i < N; i++)
c[i] = a[i] + b[i];
#pragma omp section
for (i=0; i < N; i++)
d[i] = a[i] * b[i];
} /* end of sections */
} /* end of parallel section */
}
Critical directive
#include <omp.h>
main() {
int x;
x = 0;
#pragma omp parallel shared(x) {
#pragma omp critical
x = x + 1;
} /* end of parallel section */
}
Thread private
include <omp.h>
int a, b, i, tid; float x;
#pragma omp threadprivate(a, x)
main () {
/* Explicitly turn off dynamic threads */
omp_set_dynamic(0);
printf(“1st Parallel Region:\n”);
#pragma omp parallel private(b,tid) {
tid = omp_get_thread_num();
a = tid; b = tid; x = 1.1 * tid +1.0;
printf(“Thread %d: a,b,x= %d %d
%f\n”,tid,a,b,x);
} /* end of parallel section */
printf(“Master thread doing serial work
here\n”);
printf(“2nd Parallel Region:\n”);
#pragma omp parallel private(tid {
tid = omp_get_thread_num();
printf(“Thread %d: a,b,x= %d %d
%f\n”,tid,a,b,x);
} /* end of parallel section */
Reduction clause
#include <omp.h>
main () {
int i, n, chunk;
float a[100], b[100], result;
n = 100 ; chunk = 10 ; result = 0.0 ;
for (i=0; i < n; i++) {
a[i] = i * 1.0 ; b[i] = i * 2.0;
}
#pragma omp parallel for default(shared)
private(i) schedule(static,chunk)
reduction(+:result)
for (i=0; i < n; i++)
result = result + (a[i] * b[i]);
printf(«Final result= %f\n»,result);
OpenMP
OpenMP is an API for shared-memory multi-processing programming in C, C++ and Fortran, on architectures ranging from desktops to supercomputers (Unix and Windows NT platforms). It requires special support from the compiler, which, in turn, makes it easy to adopt.
Code can be compiled for serial execution, and parallelisation can be added gradually. MCAPI provides a limited number of calls with sufficient communication functionality while keeping it simple. Additional functionality can be layered on top of the API set.
Calls in the specification serve as examples of functionality. These are not mapped to an existing implementation.
MPI is a message-passing library interface specification. Unlike OpenMP, it can be used on either shared or distributed memory architecture. However, MPI requires more changes to source codes than OpenMP, but it does not require any special compilers.
OpenMP API uses fork-join model of parallel execution. Multiple threads of execution perform tasks defined implicitly or explicitly by OpenMP directives. It is intended to support programs that will execute correctly both as parallel programs (multiple threads of execution and a full OpenMP support library) and as sequential programs (directives ignored and a simple OpenMP stubs library).
However, it can develop a program that executes correctly as a parallel program but not as a sequential one. Or it can develop a program that produces different results when executed as a parallel program compared to when it is executed as a sequential program.
Further, using different numbers of threads may result in different numeric results, because of changes in the association of numeric operations. For example, a serial addition reduction may have a different pattern of addition associations than a parallel reduction. Different associations may change the results of floating-point addition.
When an OpenMP program begins, an implicit target data region for each device surrounds the whole program. Each device has its data environment defined by its implicit target data region. Any declared target directives that accept data-mapping attribute clauses determine how an original variable in a data environment is mapped to a corresponding variable in a device data environment.
When an original variable is mapped to a device data environment and the associated corresponding variable is not present in it, a new corresponding variable (of same type and size as original variable) is created in the device data environment. Initial value of the new corresponding variable is determined by clauses and data environment of the encountering thread.
CORBA, or common object request broker architecture, is meant for inter-object communication between computers. It provides high abstraction and several other services. Attempts have been made to use CORBA on embedded systems, and some of its parts have been implemented in VHSIC hardware description language (VHDL). For hardware, CORBA is, however, too heavy.
Communicating entities
MCAPI specification is used for both API and communications semantic. It does not define which link management, device model or wire protocol is used underneath. As such, by defining a standard API, it provides source code compatibility for the application code to be ported from one environment to another (for example, from PC to MPSoC). Implementation of MCAPI also hides the differences in memory architectures. MCAPI communication is based on node and end-point abstraction.
MCAPI node is a logical concept that can be denoted to many entities, including process, thread, hardware accelerator or processor core. Nodes are always unique and statically defined at the time of design. Each node can have multiple end-points that are socket-like termination points. For example, an encryption node could be implemented as a single thread receiving plain text from one end-point, and sending encrypted data via another.
End-points are defined with a tuple <node_id, endpoint_id>, and can be created at run time. MCAPI channels can be dynamically created between pairs of end-points. However, channel type and direction cannot be changed without deleting and recreating the channel. Multi-cast and broadcast is not supported.
Communication types
MCAPI defines three types of communication as explained next:
- Messages: connection-less datagrams
- Packet channels: connection-oriented, uni-directional, FIFO packet streams
- Scalar channels: connection-oriented single-word, uni-directional, FIFO packet streams
Messages are flexible, and useful when senders and receivers dynamically change and communicate infrequently. These are commonly used for synchronisation and initialisation.
Packet and scalar channels provide lightweight socket-like stream communication mechanisms for senders and receivers with static communication graphs. In multi-core, these channel APIs provide a low-overhead ASIC-like, uni-directional FIFO communications capability.
MCAPI messages transmit data between end-points without first establishing a connection. Memory buffers on sender and receiver sides are provided by user application. These messages may be sent with different priorities.
Multi-processor system-on-chip
An MPSoC platform (Fig. 2) includes two processing elements (PEs), HIBInetwork as well as direct memory access (DMA) interfaces for IP blocks (HIBI PE DMA) and external memory (HIBI MEM DMA). Processors have local, private instruction and data memories. Inter-processor communication is implemented using message-passing.
The architecture is in an FPGA on a development board connected via PCIe to a PC, or embedded CPU board. The platform is synthesised to Altera’s Arria II GX FPGA development board at 100MHz.
A regular PC (2.4GHz, 1024MB) running Debian GNU/Linux 5.0.6 is used for application development and FPGA synthesis, to demonstrate that an application code can easily run either on PC or Nios. This is because MCAPI takes care of inter-processor communication, for PCIe, HIBI or any other. Hence, applications can be developed in a workstation environment that allows simpler debugging. Then, application code can be transferred to the FPGA or be distributed among PC and FPGA processors.
A simple pseudo code example below shows how the virtual node for a discrete cosine transform (DCT) hardware IP block is handled. The IP block is given a unique node number at the time of design; 1 in this case. By default, MCAPI send_msg function calls the driver of DMA controller (C-macro HPD_send), but for this virtual node number, it forwards execution to a DCT driver. This eventually calls HPD_SEND function, perhaps multiple times, to configure the DCT and send raw data to be transformed.
The same procedure is easily repeated for other accelerators.
Pseudo code
send_msg(…) {
…
switch(node_id){
case ‘1’ :
…
dct_drv(…);
…
default :
…
HPD_SEND(…);
…
}
}
Functions
Connection-less messages and packet channel API functions have blocking and non-blocking variants. For example, mcapi_msg_recv(…) function blocks execution of the application node until all message data has been received. Non-blocking variants return immediately and, hence, their names are denoted with i.
Required buffers are statically reserved at compile time just like end-points and channels to increase overall reliability and ease of debugging. Applications must take care of data alignment, endian-ness and the internal structure of messages.
API of the framework has an elaborate structure and is very well-organised. It gives programmers multiple ways to access the services offered by the framework. Each access to the framework is made by using tasks.
Task
A task corresponds to a single processing operation. It is associated with one or many inputs that are available on different channels. If all inputs associated with a task are activated (available), then that task is activated and is queued up for execution.
An input option marked as final is made available. If a task has an input marked as final, when this input is activated, the corresponding task is activated irrespective of the status of other associated inputs.
All functionalities associated with a task are provided in the task. This forms an important part of the API. Processing by each task is performed by overloading its execute method.
Task input
This is an essential part of each task. Data to be processed are passed on to a task as inputs. Inputs are associated with channels. The relation is 1:N. Here, one input is associated with only one channel, and each channel can be associated with N inputs.
Functionalities are provided in the task input. It is possible to control activation of an input by specifying a threshold for the number of activations. There is also a flag indicating an input as final, which, when available, activates the task irrespective of the status of other inputs. This is included as a time-out mechanism to avoid a task from waiting for more than a pre-decided time.
Task channel
This is the base for data container implementation. It stores and distributes the data for multiple tasks. Each channel can be associated with more than two inputs. A push method is provided, which notifies all associated task inputs that a new set of data is available on the channel.
In a practical scenario, many sensors associated with a satellite are designed to send data at a specific time. To serve such recurring process requests, a task event is provided in the API.
Task events are not tasks. These are an extension to the task channel. By default, these are designed to execute a push method to push data on to the channel at a specified time. Two types of events are supported by the framework, one which executes on a periodic basis and other which is executed after a specified time lapse after the call to reset that channel is made.
Bare-metal porting of the tasking framework on a board means programming without various layers of abstraction or, as some would call it, programming without an OS.
The application is the only software running on a processor in bare-metal implementations. This is because an OS uses more resources like RAM and flash for a simple application. These resources are available in limited quantity when working with embedded systems.
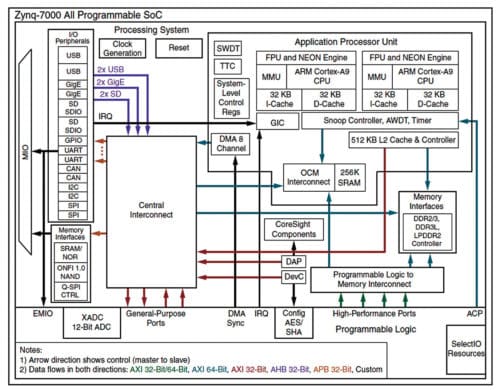
The application processor unit (APU) used is ARM Cortex A9 processor, which is based on ARM v7 architecture.
Cortex-A9 MPCore
One to four Cortex-A9 processors in a cluster and a snoop control unit (SCU) can be used to ensure coherency within the cluster. A set of private memory-mapped peripherals, including global timer, watchdog and private timer for each Cortex-A9 processor is present in the cluster.
An integrated interrupt controller is an implementation of the generic interrupt controller architecture. Its registers are in the private memory region of Cortex-A9 MPCore processor.
The SCU connects ARM Cortex processors to the memory system through AXI interfaces. It is an important element in maintaining cache coherency-related issues. ARM processors have a shared L2 cache and independent L1 caches. When working in multi-core mode, coherency becomes an important issue to address. The SCU is clocked synchronously and at the same frequency as the processors.
Functions of the SCU are:
- Maintain data cache coherency between Cortex-A9 processors
- Initiate L2 AXI memory accesses
- Arbitrate between Cortex-A9 processors requesting L2 accesses
- Manage ACP accesses
The SCU on Cortex A9 does not provide hardware management of coherency on the instruction cache.
Generic interrupt controller (GIC)
The processing system includes a GIC that manages and assigns the interrupts that happen on the system. The interrupt controller is a single functional unit located in a Cortex-A9 multi-processor design. There is one Cortex-A9 processor interface per Cortex-A9 processor. Processors access it by using a private interface through the SCU.
The GIC provides the following:
- Registers for managing interrupt sources, interrupt behaviour and interrupt routing to one or more processors
- Support for ARM architecture security extensions, ARM architecture virtualisation extensions
- Enabling, disabling and generating processor interrupts from hardware (peripheral) interrupt sources
GigaX API for Zynq FPGA
Real-time processing of gigabit Ethernet data in programmable logic is a time-consuming challenge that requires optimised drivers and interface management. SoC devices provide hardware resources that allow this communication, but these lack general-purpose software applications needed for implementation.
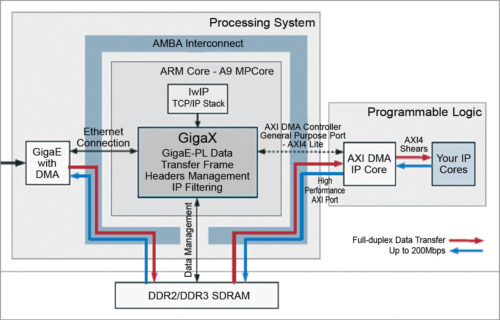
GigaX is a lwIP-based API for Xilinx Zynq SoC that establishes a high-speed communication channel between GigaE processing system port and programmable logic. Running in one of the Zynq ARM cores, GigaX processes network and transport headers, and manages SDRAM, Ethernet DMA and AXI interfaces to set up a robust full-duplex data link through the processing system at 200Mbps.
Software API also implements IP filtering and TCP/UDP headers management to allow using the device as an Ethernet bridge, programmable network node, hardware accelerator or network offloader. GigaX is easy to install as a library in SDK project. It can control GigaE peripheral and AXI DMA interface to enable direct communication between Ethernet and VIVADO IP cores.
Based on the open source lwIP stack, GigaX controls Zynq GigaE peripheral to send and receive Ethernet frames to and from the SDRAM via AMBA interconnect bus. After performing IP filtering, Ethernet data is sent to PL through a high performance AXI port, which is also used to send processed data back to the processing system.
Processing system-programmable logic transfer uses AXI DMA implemented in the programmable logic and controlled by GigaX through a general-purpose AXI4-Lite port. Network headers can be kept or removed before reaching the programmable logic. GigaX also allows generation or modification of IP headers of the data received from the programmable logic. Complete full-duplex communication based on DMA and AXI ports allows high-speed data transfer without overloading the ARM processor.
AXI4-Stream interfaces are used to transfer Ethernet data to and from IP cores. GigaX data caching system can manage data peaks over maximum transfer rate, ensuring stable communication of variable data flows. The API implements a software watchdog timer to recover from unexpected situations.
V.P. Sampath works as a consultant who develops hardware/software co-design tools. He is an active senior member of IEEE and a member of Institution of Engineers.





