

When we talk of Internet of Things, we talk of Cloud Computing almost in the same breath. This is a bit surprising because not all IoT-enabled devices have to be monitored and controlled by a centralized application deployed on a far-off data center. For example, home automation and consumer durables vendors are starting to offer mobile apps that constitute a part of the Human-to-Machine Interface (HMI) for controlling such home appliances. At the same time it is likely that these consumer durables are also sending data over to the vendor’s data center, periodically, in order to enable proactive maintenance.
Extrapolating this pattern to a wider range of scenarios, IoT applications are beginning to embrace a multi-layer architecture for control and data analysis. Data generated from devices, including sensors and industrial equipment, is being processed in one or more compute nodes located at a logical boundary between the device farm and the Internet, usually referred to as the ‘edge’. And then some of the data is being relayed over from the edge to a remote data center for further analysis and action. The communication between the devices and the edge nodes may be achieved using WiFi, if the devices are WiFi-enabled, or based on specialized protocols like LoRa, or even serial ModBus in an industrial environment. However, the communication between the edge nodes and the Cloud-resident application happens over a Wide-Area TCP-IP network.
As IoT is evolving, the ‘edge’ devices with computing power is being manifested in various forms:

- An Intelligent Gateway: A Gateway node is primarily responsible for intercepting data from devices and transmitting it to a cloud-enabled application over TCP-IP. Many Gateway vendors, like Dell manufacture gateway nodes that can filter, aggregate, and apply rules to the device-generated data before transmitting it over to the cloud.
- Edge Computing Nodes: In an industrial environment, Programmable Automation Controllers (PACs) are employed to run a pre-defined set of control functions on a set of plant equipments. When these plant equipments are IoT-enabled, the PAC nodes may be additionally programmed to run data processing functions on data transmitted by such equipment. This capability is referred to as Edge Computing.
- Fog Nodes: ‘Fog’ refers to a set of computing nodes that perform a large subset of data analytics and control functions that would normally be performed by an application on the cloud, that receives large volumes of data from IoT devices. However, these nodes are located closer to the IoT devices, typically in the same Local Area Network. And unlike gateways and edge nodes, the fog layer consists of both storage and compute capacity.
Typically, for an IoT-enabled device farm, the fog layer complements the cloud-hosted applications. For example, the fog layer may act upon data streams and send out control signals on a frequent basis, while relaying part of the data to the cloud where large volumes of historical data can be stored, analyzed and modeled for running predictive analytics.
Obviously, the fog layer, or ‘Fog Computing’ has found its place in IoT architecture, out of necessity.
In many IoT applications data generated from millions of sensors and other devices is too enormous to be sent over to a cloud-based analytics engine at regular intervals. However, the application still needs to analyze data and send out control signals in real-time, possibly within milliseconds. A smart power-grid is one such application. A fog layer can decentralize and localize data analytics tasks within smaller segments of the power grid, while still relying on a remote data center for modeling power consumption patterns.
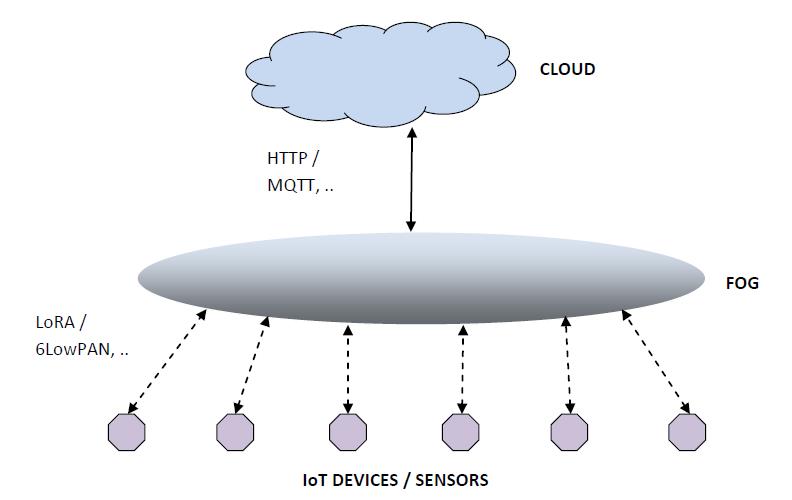
Deploying a fog layer may be advantageous in the following scenarios:
- Scarce Bandwidth or Inefficient Use of Bandwidth: Not only is it inefficient to transfer every byte of device generated data from millions of sensors to the cloud, but also some of these sensors may be installed in locations with poor internet connectivity.
- High Network Latency / Low Event-to-Action Time Constraints: Both the volume of data as well as factors related to Internet connectivity may lead to high latency in analyzing and acting upon device data. In many applications the control signals required to avert failures in a system may have to be sent out within milliseconds.
- Data Stream Analysis: Fog nodes nearer to a device farm may be able to analyze streaming data faster and more efficiently compared to a an analytics engine on a remote data center.
- Fault-tolerance: A fog layer can add redundancy to data processing capacity over and above the cloud nodes, especially where network connectivity to the cloud is unreliable.
But then designing a fog layer for any and every IoT application doesn’t make sense. The type of IoT applications that employ a wide and dense network of devices generating data at high volumes and velocity, can take advantage of Fog Computing. Examples of such applications would be:
- Smart Cities
- Smart Transportation
- Fleet Management
- Smart Power Grids
- Oil Refineries
- Meteorological Systems
On the other hand, it would probably suffice to send data from medical sensors or wearables directly to a cloud-based application.
Fog Computing Architectural Patterns
The Internet that connects us today was designed to be a data network, that over a period of time supported live video streaming and other bandwidth-hogging applications. But when it comes to billions of devices transmitting data in real-time over to the cloud, its capacity limits will be tested. A thousand smart cities sending surveillance data at high frequency could congest even a 5G network of the future. Fog computing can lead to more sustainable bandwidth utilization by transmitting only essential data over the Internet and processing the remaining data within a local network. This will help reduce network congestion in the long run.
Secondly, the more data that we send over the WAN the more exposed we could be in terms of data security. Indeed some of the data generated by devices in IoT applications could be sensitive. By reducing the data volume transmitted over the Internet, the data security risks can be minimized.
The OpenFog Consortium is involved in promoting architectural standards in fog computing. These standards when fleshed out and emulated, will hopefully lead to better IoT applications that also tap onto the Internet in a more efficient and secure fashion.
Interestingly, the OpenFog architectural patterns envisage multi-layered, hierarchically distributed clusters of fog nodes. Each cluster may process data from a geographical segment of the device farm, and higher-layer fogs may collate and process data filtered through the lower layers. Secondly, the layers may actually perform separate logical functions such as Monitoring and Control, Operational Support and Business Processes.
What’s exactly a Fog Node?
A fog node is an Internet-connected node with commensurate computing and storage capacity. But this is where the action lies. On one hand server and networking equipment vendors would like to play a role in carving out the right kind of computing capacity to be deployed at the fog layer. On the other hand, analytics vendors will be interested in plugging in the built-in analytics, particularly real-time stream processing capabilities, together with secure communication and data security features.
We are already seeing this sort of an ecosystem taking shape. Cisco, the company that actually coined the term ‘Fog Computing’, is partnering with IBM to bring together computing capabilities at the edge of the network equipped with IBM’s Watson Analytics service.
Another company to watch out for in this space is actually an independent software vendor named FogHorn. FogHorn specializes on the analytics suite that a large cross-section of IoT applications, particularly Industrial IoT applications, can benefit from. The analytics suite includes machine learning for monitoring, diagnostics, performance optimization, etc. Although FogHorn is focused on the software stack, its partnership with hardware vendors will be key in offering a Fog Computing infrastructure.
Well, it may also be possible to build your own fog until off-the-shelf offerings hit the market.
Challenges and Open Issues
Fog Computing will bring up a larger set of distributed nodes to manage and monitor, and twice the set of network interfaces – one interface between the devices and the fog layer, and another between the fog and the cloud. Tools for provisioning, managing and securing the fog layer, and integrating it in the continuum between the devices and the cloud, will have to be developed. This is no different from how cloud computing evolved, except that the fog nodes are typically more constrained than full-blown computing devices on the cloud. And the fog layer may not be as elastic as the cloud layer. Security standards for communication between devices and the fog nodes will be a key area of research.






very interesting and smart