

ARM is a family of instruction set architectures used in making computer processors developed by ARM Holdings. It is based on the reduced instruction set computing architecture which is commonly called as RISC. In 2010, ARM Holdings, plc reported shipments of approximately 6100 million ARM-based processors to manufacturers of chips based on ARM architectures, representing 35 per cent of digital TVs and set-top boxes, 95 per cent of smartphones and 10 per cent of mobile computers. As of 2014, ARM is the most widely used 32-bit instruction set architecture in terms of quantity produced.
Millions of electronic gadgets around the world invade our daily life and we have become completely dependent on them for performing most of our work. A very nice example to justify this would be a smartphone that everyone is quickly adapting to, due to its varied features. These gadgets are the pleasing results of the ceaseless developments in the field of electronics. Most of these gadgets are fitted with embedded processors that not only occupy less space but also ensure that users get a smooth experience whilst using the device. The ARM processor cores used in most of these devices follow an architecture that helps them perform efficiently.
Nowadays, there are several embedded architectures in use such as ARM architecture developed by ARM Ltd, Atmel’s AVR architecture, TI’s MSP430 architecture and many more. However, the extensively used and most popular embedded architecture amongst many companies is the ARM Ltd’s ARM architecture.


History of ARM
Advanced RISC machine (ARM) is the first reduced instruction set computer (RISC) processor for commercial use, which is currently being developed by ARM Holdings. The history of ARM processor dates back to 1983 in England when Acorn Computers Ltd officially launched an Acorn RISC Management project after being inspired to design its own processor by Berkeley RISC, one of the high-impact projects under ARPA’s (Advanced Research Projects Agency, now converted to DARPA) VLSI project, dealing with RISC-based microprocessor design led by David Patterson who coined the term ‘RISC.’ As the name suggests, it does not mean that the processors with less than 100 instructions are qualified to RISC category, but instead they should have an highly optimised instruction set.
ARM in the beginning was known as Acorn RISC machine. With VLSI Technology Inc. as its silicon partner, ARM came up with ARM1, the first ARM silicon on April 26, 1985, which was used as a second processor to the BBC Micro to develop the simulation software to finish work on the support chips (VIDC, IOC and MEMC) and to increase the operating speed of the CAD software used in development of ARM2. Apple, whilst developing an entirely new computing platform for its Newton, a personal digital assistant, found that only Acorn RISC machine was close to the requirements needed for implementation, but since ARM had no integral memory management unit, Apple collaborated with Acorn to develop ARM.
The result of this collaboration was that both Acorn Group and Apple Computer, Inc., with 43 per cent share each, and VLSI Technology, Inc. as an investor, a separate company, ARM Ltd, was established in 1990. Also, the advanced research and development section of Acorn was employed here. After that time, ARM became the acronym for advanced RISC machine.
But what was Berkeley RISC?
In the past, CISC microprocessor cores like Motorola 68000 used only a subset of the available instruction set; therefore most of the decoding circuitry for the never-used instructions was wasted. But in RISC, CISC was replaced with multiple registers to speed up the execution since access to these registers would take less cycles than memory access needs, outperforming CISC.
Considering the case of ADD instructions in which CISC would appear in different formats where one would be meant for adding the numbers in two registers and placing the result in third, whilst the other would allow to add two numbers stored in the main memory and store the result in a register, offering wide variety of instructions to perform the required operations and providing several options as operands.
But in the case of RISC designs, the ADD would always take registers as operands, which creates a necessity for the programmer to write additional instructions to load the values from memory whenever required. Now, the Berkeley RISC was able to provide good performance utilising pipelining and register-windowing technique. In register windowing, the CPU contains a large number of registerss around 128, together called a register file, whilst the group of eight registers is called a window. But a program can only use one window, thereby allowing fast procedure calls. The call simply moves the window down to the set of eight registers used by that procedure and the return moves the window back.
After that time, RISC has seen a lot of developments proving its simplicity over CISC. Here are some of the features of RISC:
1. Large general-purpose 32-bit register banks
2. Fixed 32-bit instruction size
3. Hard-wired instruction decode logic instead of microcoded ROMs
4. Single-cycle execution is possible
5. Pipelined execution
6. Easier to prototype
RISC features can be introduced in CISC processors but would require much more hardware. A typical RISC architecture consists of a large uniform register file, load and store architecture, simple addressing modes and uniform fixed-length instruction fields. Due to this characteristic, we achieve high performance, low code size, low power consumption and low silicon area.
What features does ARM provide?
British multinational semiconductor and software design company, ARM Holdings plc, offers complete solutions that are essential for the manufacturing process, but the company does not manufacture ICs. Moreover, it provides software development tools under the brand Keil and RealView. It also provides ARM architecture licensing for the companies that want to manufacture ARM-based CPUs or ‘system-on-chip’ products.
The ARM architecture is a simple hardware design allowing things to be left off the chip. It helps in creating small die-sized chip which helps in considerably reducing the cost. Its low cost, simple pipeline construction and the freedom to put the design point where the designer finds it suitable for low-power consumption adds onto the benefits it provides for embedded applications.

ARM allows an instruction set called ‘Thumb’, which compresses 32-bit instructions to 16 bits, enabling programs to be coded much more densely than standard RISC instruction sets. Processors enabled to execute ‘Thumb’ also allow 32-bit instructions to run on the same hence allowing 16-bit and 32-bit instructions to mix together without affecting the performance, maintaining powerful computing capabilities.
/arm/chapter3.htm)
ARM designs and licences intellectual property (IP) instead of manufacturing the chips. Two types of licences that ARM provides are ‘implementation licence’ and ‘architecture licence.’ Implementation licence provides information to design integrated circuit containing the ARM core. The architecture licence enables the licencees to design their own processor with ARM instruction set architecture.
ARM cores are simple compared to other processors since it can be manufactured with few transistors. ARM is a 32-bit instruction set architecture. Today, many embedded applications like smartphones, set-top boxes, digital televisions and digital cameras use an ARM processor due to their cost-effectiveness and low-power consumption. ARM architecture is compatible with all four major operating systems, i.e., Symbian OS, Palm OS, Windows and Android OS.
The instruction sets in ARM processor are classified as ARM instruction set, Thumb instruction set and Jazelle mode. ARM mode is a standard 32-bit instruction set. Thumb instruction set is a 16-bit compressed form that provides better performance than complex instruction set computers (CISCs). Jazelle DBX (direct bytecode eXecution) allows some ARM processor to execute Java bytecode.
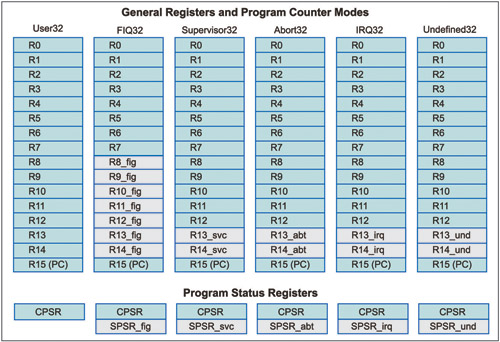
An ARM processor consists of 31 general-purpose 32-bit registers. Sixteen registers, namely R0-R15, are visible, which means they can be modified by the user whereas other registers help to speed up the exception process. Some registers play some special roles, like R14 acts as a link register (LR), R15 acts as a program counter (PC) and R13 acts as a stack pointer.
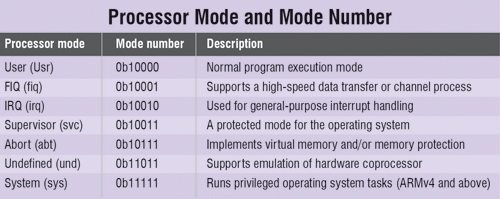
There are seven modes of operations as shown in the box (on previous page). Their modes are categorised as user mode, privileged mode and exception mode. User mode is a normal program execution mode in which the system resources are unavailable. If some exception occurs, then the mode is changed to the exception mode. In exception mode, all system resources are available.
There are two important registers in ARM, namely current program status register (CPSR) and saved program status register (SPSR). CPSR is similar to PSWR register in 8051 microcontroller which indicates some important flag bits like carry bits and zero flag bits as shown in Fig. 1, whereas SPSR is used in exception modes. Whenever exception occurs, the contents of CPSR are copied to SPSR. The organisation of registers in an ARM processor is as shown in Fig. 2.
The ARM architecture has evolved through many stages; the smartphones employ ARMv5 architecture and the later releases. Hardware floating-point unit (FPU) is the major change brought in ARMv7 to provide more speed than the software-based floating point. Even DSP instructions were added to the set to improve the ARM architecture for use in digital signal processing (DSP) and multimedia applications. In ARMv7, even the Thumb-2 feature, to obtain code density as Thumb and performance as ARM instruction set, was added that extends 16-bit Thumb instruction set with 32-bit instructions, producing instruction sets of variable lengths.
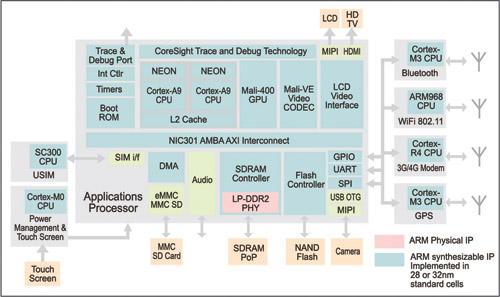
A new ‘unified assembly language’ (UAL) support is provided to generate Thumb-2 or ARM instructions, whichever is required from the same source code. The new ARMv8 has undergone a considerable change by using 64-bit architecture and cryptography instructions supporting AES and SHA-1/SHA-256, and even allows 32-bit applications to be executed. An optimised ARM smartphone block diagram is shown in Fig. 3 (Source: www.arm.com).
Therefore this ARM architecture with brilliant features is widely adopted by many organisations (more than 2500 organisations are licenced with IP), as a result of which it is the world’s leading semiconductor IP supplier, having over 40 billion ARM processor based chips shipped to date, providing each user with smooth experience. So with ARM and its ever-improving architecture, the future of computing devices not only has a better scope by being cost-effective, but they also have plenty of features to offer.
The authors are BE final year students at NMAMIT, Nitte





