

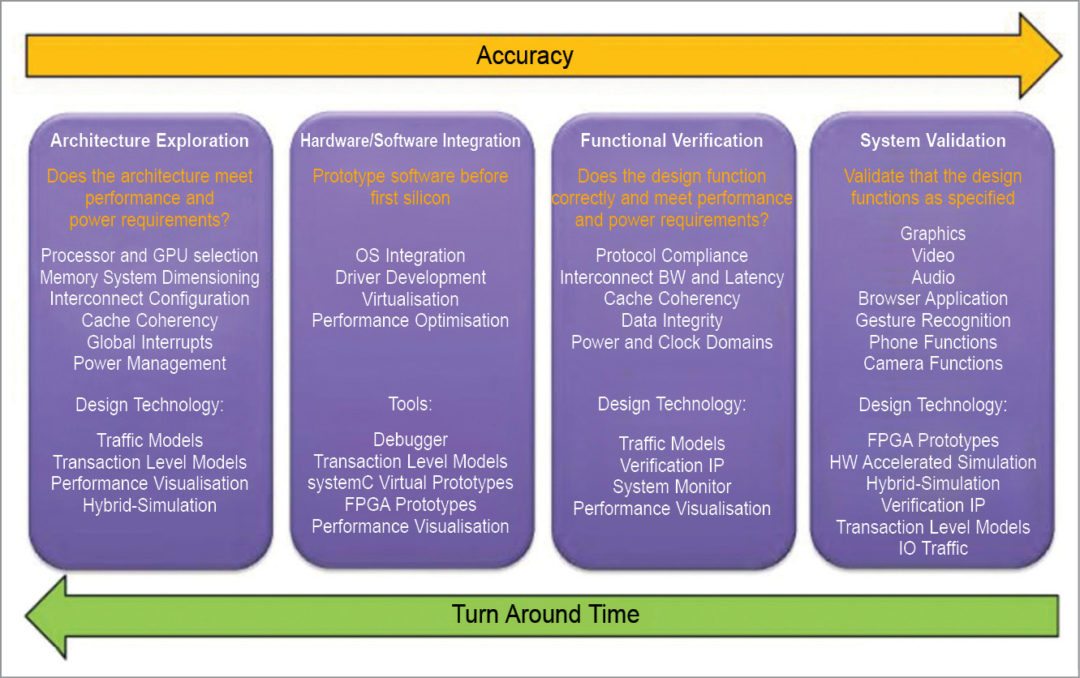
Hybrid emulation is a technique that combines emulation and virtual prototyping to enable earlier architecture optimization and software development, as well as higher performance for software-driven register-transfer level (RTL) verification even when critical IP RTL is not available. Hybrid emulation is done when part of the system is run in the emulator and the other part is run in a virtual prototype.
Hybrid emulation with a high-performance emulator can run at multi-megahertz speeds, fast enough to provide a productive debugging experience. When using the hybrid emulation system for software development, you require access to full-visibility debug features of the emulator, where some of the design is modeled. This allows a full system-level view for verification.
Hybrid emulation enables system-on-chip (SoC) development teams to take full advantage of their investments in a high-performance emulation system across their entire project to better meet increasing software, verification and competitive challenges. Typically, a model of the processor is run in the virtual platform and then the rest of the design is modeled by running the RTL on the emulator.

Benefits of Hybrid Emulation
Hybrid emulation offers several benefits for SoC architecture, software and verification teams. For architects, it provides a mechanism to implement key elements of the SoC that are only available as RTL in a high-performance, cycle-accurate manner to support their architecture optimization efforts. Users can choose cycle-accurate, approximately-timed or loosely-timed synchronization between the virtual prototype and the emulator to make speed/accuracy trade-offs.
Three main uses for hybrid emulation are architectural validation with accurate models, early software development and hardware verification.
In architectural validation with accurate models, high-speed models used to model processors are only functionally-accurate and not cycle-accurate, and you cannot get accurate performance or accurate performance data from these at that level of detail. Of course, you could just run the RTL of the processor on a simulator, but that is too slow.
In early software development, transactional-level models are often not available, are too low or do not exactly match the RTL for the block. But a hybrid approach with the processor in a virtual platform and all or most of the rest of the design in the emulator is fast enough for productive software development.
Hardware verification allows running actual software load.
Architectural Validation
For SoC architecture validation, you, as a user, have to link a high-performance emulator like ZeBu Server-3 to a virtual prototype exploration tool like Platform Architect MCO. ZeBu Server is the industry’s fastest emulation system. ZeBu solution includes ZeBu Server-3 emulator and a broad portfolio of ZeBu transactors, memory models and ZEMI-3 transactor compiler for rapid development of virtual system-level verification environments.
ZeBu provides comprehensive debugging with full signal visibility and Verdi integration and supports advanced use modes including power management verification and hybrid emulation with virtual prototypes for architecture optimization and software development.
Platform Architect MCO enables system designers to explore and optimize the hardware-software partitioning and configuration of the SoC infrastructure, specifically the global interconnect and memory sub-system, to achieve the right system performance, power and cost.
Using a high-performance emulator like ZeBu Server-3 with a virtual prototype exploration tool like Platform Architect MCO, testing typically consists of running application software tests on processor sub-systems in the emulator to drive simulation and monitoring performance. This confirms whether optimized configuration of the architecture design chosen during exploration meets the required performance metrics.
Verdi integration provides the powerful technology that helps comprehend complex and unfamiliar design behavior, automate difficult and tedious debug processes and unify diverse and complicated design environments. ZeBu Server module emulates 60M gates in nine emulation chips. The components fit better, and fewer design nets get cut. It has less interconnect hardware. Highest performance is two to five megahertz, and it has low power, small size, gets latest processes every two years and is reliable.
Interconnect and memory sub-system peripherals are often modelled in Platform Architect MCO, with cycle-accurate CPU sub-systems modeled in ZeBu Server-3. In ZeBu world, various timing domains maintain their relative clock ratios. Operation in a fully-timed synchronization mode provides full cycle accuracy.
You can use this environment to run a variety of processing loads and data streams, and quickly analyse relative performance trade-offs between various factors like cache sizes and number of processors. Typical results might show the impact on the performance of variations in the number of data streams and processing loads.
Early software development and software-driven verification
Hybrid emulation enables pre-silicon software development while part of the RTL design is still under development. It is also useful for system-level hardware-software co-verification. Virtual prototypes support the use of instruction-accurate SystemC/C++ processor models and other loosely-timed SystemC TLM-2.0 models.
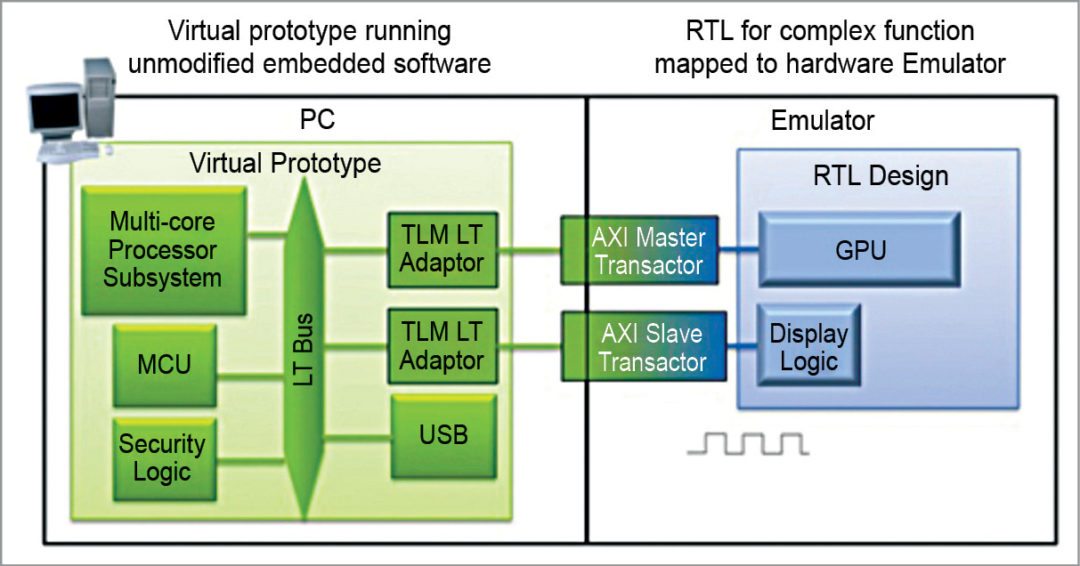
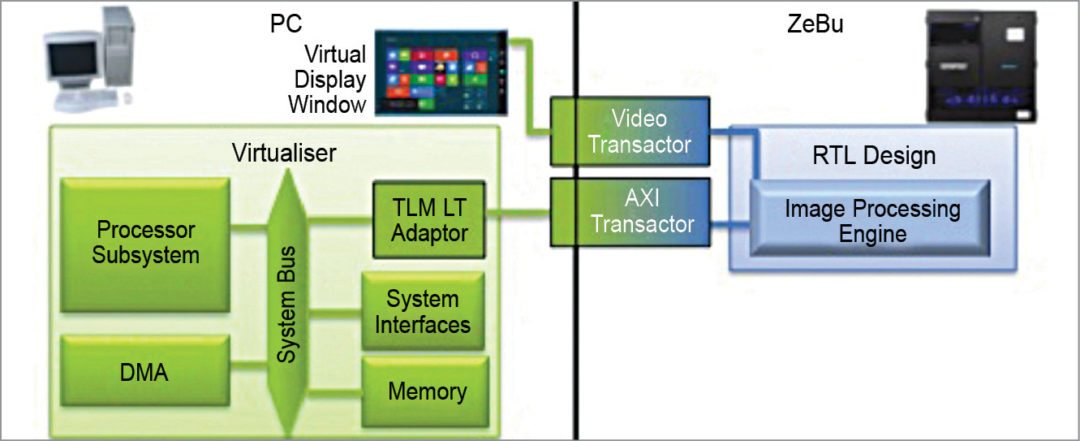
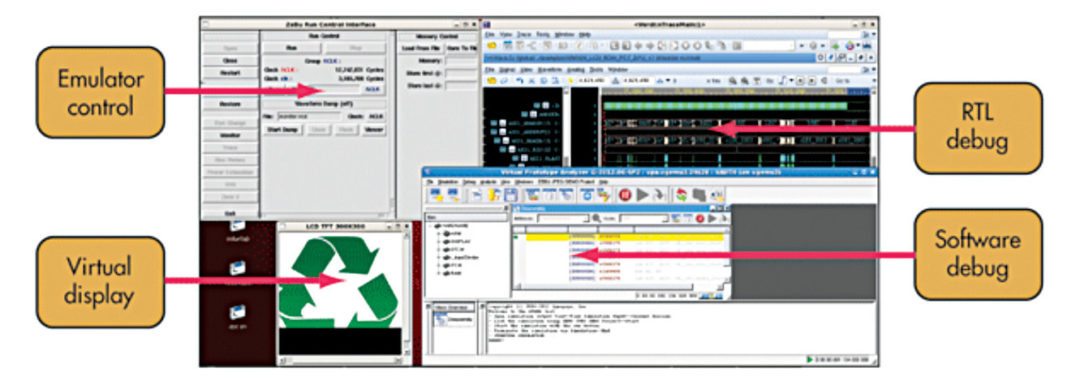
Such models remove the need to wait for silicon to begin developing or validating system software. In the example given in Fig. 4, a video-processing system running in emulation is debugged with image decompression and LCD driver software running on a virtual prototype, displaying real-time video output on virtual display.
The software team can leverage these functional models in a virtual prototype developed using a virtualiser, and the resulting software development kit is called a virtualiser development kit, with some pieces of the design for which no SystemC models exist. These are represented as RTL in a high-performance emulator like ZeBu Server-3.
This hybrid emulation environment allows the software design team to begin developing, running and testing its software at multi-megahertz speeds long before silicon is available. The hybrid emulation mode is also valuable for software-driven verification when the RTL for the processors is not available or when you wish to free up some of the emulation system capacity by offloading processor emulation models and other blocks of the design to the virtual prototype.

In the hybrid emulation environment, while the processor models are executing software in the virtual prototype, the emulator also provides full visibility into the design’s RTL to allow simultaneous verification of the non-processor design elements. In such environments, typically, embedded software performs as an executable test bench in combination with emulation focused transaction-level tests using virtual components, C++ test benches, software traffic/packet generators or physical testers.
To achieve the hybrid emulation speed required for software development and testing within the virtual prototype, several parameters are not modelled with 100 per cent accuracy in a virtual prototype, such as detailed timing. Consequently, synchronisation mode for hybrid emulation for software development is generally loosely-timed or approximately-timed, which can still provide the accuracy level needed for software development as well as the performance expected.
A SystemC loosely-timed processor model must describe processor behaviour accurately enough to execute real, unmodified software images, and model how the system would boot the operating system, support actual drivers and run applications.
Software development or software-driven verification
In using hybrid emulation for software development or software-driven verification, the processors are modelled in the virtual prototype using SystemC loosely-timed models such as ARM Fast Models, while major pieces of the design may be modelled in the emulator.
The processors and sub-systems are connected to emulated RTL blocks through transactors for bus-level communication with TLM-2.0 wrapper or adaptor. Software debug is accomplished using traditional software development tools such ARM DS-5, Lauterbach Trace32 or inherent tools of the virtual prototype environment.
For software development teams, hybrid emulation enables you to perform multi-core software debug in a very high-performance environment without waiting for silicon or transaction-level models to be available. For verification teams, hybrid emulation enables high-performance software-driven verification even when processor RTL is not available for emulation, while freeing emulator capacity by moving processor models to the virtual prototype.
Since the advent of transaction-level modelling, it has been possible to create a virtual platform of a CPU sub-system, which trades off accuracy for speed in order to provide an early target to test software. Traditionally, the make or break of such virtual platforms would depend on the availability of SystemC models for various components; it would simply take too long to generate a trustworthy model for, say, a new coprocessor, so the benefit of early software simulation would be lost. Growth of SystemC model libraries for popular functions such as ARM’s Fast Models has helped fill those gaps, but what about the new functions unique to the new SoC?
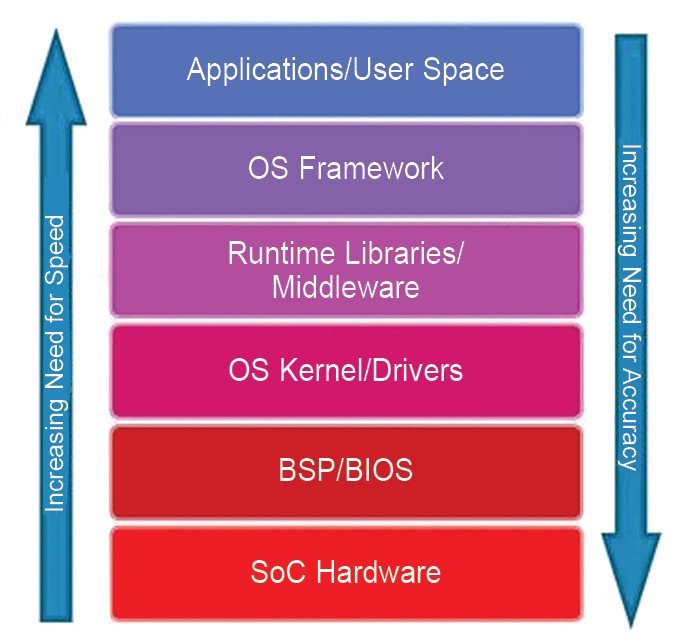
Designers and commentators often use the term software freely, but without specifically defining what they mean. An SoC, like most other embedded processing systems, has different kinds of software, operating and inter-reacting at different levels of a software stack and across multiple processors. User space (Fig. 7) including applications appears at the top of the stack and rests upon lower layers, which are increasingly concerned with the operating system kernel and the hardware as you reach lower levels.
Choose any level in the stack
If you wish to develop software at that level, then you need a representation of all levels below upon which to run it. Ideally, that might be the real lower-level software running in real system hardware; but when that is not available, a model must be created instead. Well, it should have just enough accuracy at a given level in order to maintain the deception that the software at that level is running in the real system; any accuracy greater than that will just be a waste of simulation time.
Software at the lowest levels of the stack is aware of SoC hardware and masks any hardware dependencies from higher-level software, thereby allowing greater portability and reuse of programs in the user space. Software at these lower levels is called hardware-dependent software. A model on which you can test aspects of hardware-dependent software, such as a BSP or BIOS, needs high accuracy, and may include a cycle-accurate model of the relevant hardware itself.
This may be in an RTL simulator, emulator or FPGA based prototype, depending on how fast you need to run. Software at the highest levels of the stack, such as apps and other user space programs, need the least accuracy, and can therefore run at the highest speeds.
Virtual platforms and FPGA-based emulation
The task of a virtual platform is to have just enough accuracy to support the level of software being run on it. This is largely achieved by modelling the behaviour and inter-block communications at transaction level, which makes these inherently faster than equivalent cycle-accurate representations. If you have the necessary models or libraries of models usually written in SystemC, then you can create a virtual platform for any SoC. Such libraries of SystemC models are available as open source or commercial packages such as the system-level library.
SoC designs are dominated by ARM IP, so you will need models of ARM cores and bus sub-systems. ARM supplies such models by the name of Fast Models, and these models are already in wide use in virtual platforms worldwide.
You have seen how RTL can be used to replace missing transaction-level models. Using Standard Co-Emulation Modelling Interface (SCE-MI), you can create a hybrid emulation platform in order to substitute a transaction-level model for not-yet-available RTL blocks. In some cases, you might not have access to the RTL for the CPU IP. In such cases, you can either use Fast Models or mount a hardware test chip into the emulator. However, the latest CPU IP often has a virtual model available well before a customer-usable test chip.
SCE-MI can be used to solve the following customer-verification problem:
Most emulators on the market today offer some proprietary APIs in addition to SCE-MI 1.1 API.
Proliferation of APIs makes it very difficult for software based verification products to port to different emulators, thus restricting the solutions available to customers. This also leads to low productivity and low return on investment for emulator customers who build their own solutions.
Emulation APIs that exist today are oriented towards gate-level and not system-level verification.
If you cannot meet performance targets with the whole SoC in an FPGA based prototype or an emulator, and if you do not need cycle-accurate behaviour within the CPU, you can replace the CPU with Fast Models running in a virtual platform linked via SCE-MI.
Virtual models of the CPU run Instruction Set Simulation (ISS) rather than model the CPU’s gate-level behaviour and, hence, perform much faster than running its RTL implemented in FPGA, or an emulator.
ARM Fast Models also represent additional device-specific functionalities such as cache coherency that a more generic ISS would ignore, but would still maintain the performance advantage. As an example, a CPU IP sub-system may typically run at 2GHz in 28nm silicon. But how fast will it run in various verification platforms?
There are many dependencies, but the CPU’s RTL might only reach 20MHz when partitioned into an FPGA based prototype, or just 2MHz in a traditional Big Box emulator—an FPGA based emulator could be somewhere between those two figures. That same processor’s virtual platform might run at a rate equivalent to more than 1GHz, although this figure is slightly misleading given that the models are untimed, so it is better considered in terms of operations per second.
The CPU or a CPU sub-system such as ARM Cortex-A53 cluster is usually delivered as pre-verified RTL, so re-verifying it fully to cycle-level accuracy may be a waste of time. All you need to do is to model the CPU’s interfaces with the rest of the SoC with cycle-accuracy, while modelling the CPU’s internal activity with untimed transactions. Operation of the CPU, its software and the overall SoC prototype will be accelerated as a result.
This use mode might also be valuable if the target FPGA hardware is running out of capacity such that you do not have room to implement all of the RTL in the FPGA hardware at once. By selectively pushing parts of the design over to the virtual side, you can not only boost performance but also free up FPGA resources.
In SoC verification, directed tests are often used in conjunction with constrained random tests in order to provide necessary functional coverage. The most sophisticated directed tests are written such that these can adapt the stimulus to reflect activity within the design under test. Such tests are often written in SystemC, so it is a short jump to consider driving these from a virtual platform running specific test software.
Verification teams often employ such software-driven tests, but this is usually assumed to be running on a processor embedded within the SoC hardware. Ability for software running on the virtual CPU to adapt stimulus to the response from the design under test is a powerful way to augment coverage, which may otherwise take a thousand times more verification cycles to reach by constrained random methods alone.
If you create a fix to some unexpected behaviour, you can test that fix in exactly the same combination of conditions that exposed the original bug. The hybrid solution drives the hardware with stimulus from the virtual side, for example, with communication messages and data in a certain protocol being extracted by the virtual model from data files on the virtual model’s host workstation. A library of such stimulus might even be built up and reused across projects.
In the same way, virtual models can access real world data from a USB port on the FPGA based hardware, for example, in order to exercise middleware, and drivers being created by software engineers on the virtual side. This would be an advantage at so-called Plugfest events, in which early developers of new communication standards such as USB 3.0 can physically connect their prototypes to those of cooperative developers of other companies. They could use the CPU and software running in the virtual part of our hybrid emulation platform in order to gain excellent debug visibility into the new driver or even PHY performance.
Emulator users and advanced users of FPGA based prototyping provide only remote access to their environments, as opposed to wheeling these into a lab environment. Many end users only work on the software aspects of the SoC and do not need access to the real world, yet they do need to interface with some cycle-accurate behaviour of the RTL running in hardware. In those situations, hardware can be maintained in closed server rooms and accessed over usual networks, perhaps even via Internet protocols in remote locations. This not only makes it easier to share time on the hybrid emulation platform across multiple users, but also isolates it from accidental misuse and shields you from any fragility in the hardware.
Partitioning an SoC across virtual and hardware platforms
In all possible use cases for hybrid emulation, there will be some blocks of the SoC design running in FPGA hardware and the rest in virtual models. In some cases, the choice will be governed by the availability of models or RTL. If you have both, however, then it will depend on the side of the virtual-hardware boundary where that particular block is placed. This leads to the critical question of where to place the boundary between virtual and physical domains.
Virtual platforms
In the SoC era, virtual platforms are commonly used for system architecture exploration and, following this, as a golden reference model for SoC verification. It turns out that virtual platforms are also very useful when it comes to firmware and software development, as virtual reference models are usually available much earlier than the SoC prototype. Co-emulation with virtual platforms offers numerous advantages to design, development and verification teams.
Advantages of co-emulation with virtual platforms are:
• Emulator replaces lacking virtual models
• Virtual platforms replace modules unavailable in RTL code
• Emulation ensures real hardware accuracy
• Emulator is faster than complex virtual model
• Virtual platforms are usually based on SystemC simulation kernel and use TLM as an interface to interconnect simulated models. The same interface is used to connect with emulated designs
Challenges
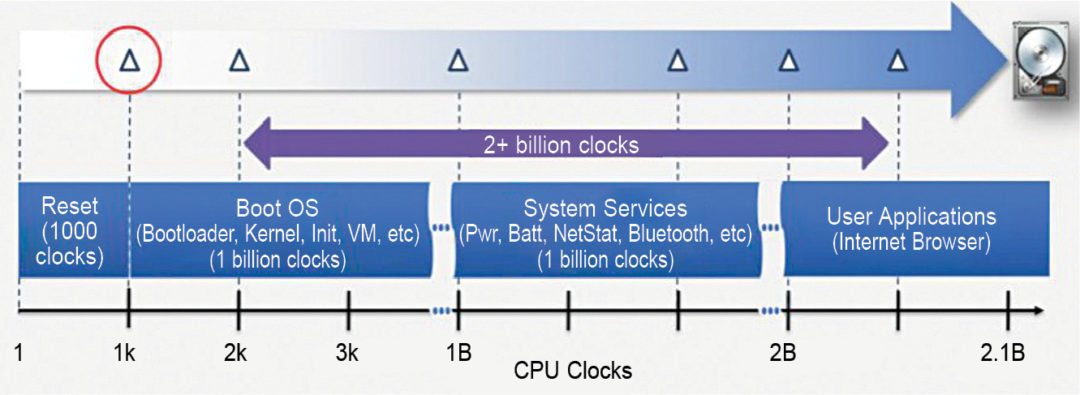
One challenge with the hybrid emulation approach is that it can generate insane amounts of data very fast. As a result, there is often a window of a million or so cycles that are recorded and can be used when a bug is encountered to investigate the root cause. But running software and emulation and doing a system boot or bringing up a Wi-Fi connection may take billions of instructions. The point at which the bug was injected by an error and the point at which it is first observed may be too far apart for the million cycle window to be useful.
Instead, ZeBu post-run debug works like the following: Every few seconds, a device under test checkpoint is made. All inputs to the system are captured. The system can then be rerun from any one of those device under test checkpoints, and is completely deterministic. This enables billions of cycles to be recorded without actually having to record these.
Feel interested? More articles are available here.





