




Persistence or data storage is a very important aspect for any enterprise or consumer software. However, in terms of speed or latency, the persistent media has always been orders of magnitude slower than the volatile memory. There is a constant effort to reduce this gap between volatile and non-volatile media. As shown in the pyramid, there has been a progression from rotating hard disks to NAND based SSD to NVMe based SSD; the speeds improved from milliseconds to 10s of microseconds.
More recently, there has been an advent of one of the most disruptive yet promising technologies – Non-Volatile Memory (NVM) or Persistent Memory (PM). Unlike most of the persistent media technologies that are block oriented, NVM is byte-addressable and have latencies close to DRAM, while densities better than DRAM. Some of the NVM technologies include Phase Change Memory (PCM) [1], Resistive RAM (ReRAM) [2] and Intel’s 3D XPoint [3]. This media is attached to the DDR bus and directly addressable by the CPU. It requires no DMA. Thus, it can be accessed as a memory using load/store instructions from applications and store your data durably!
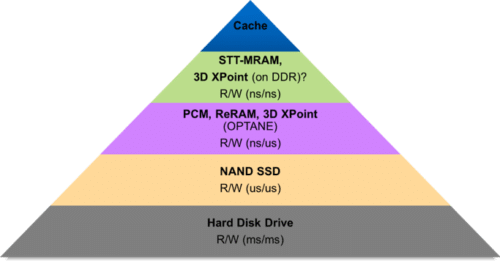

Developments in persistent memory technology
Persistent memory technology theoretically provides a great leap in speed-increase, but in practice poses some interesting software challenges. Professor Steven Swanson and his students’ study [4] found that on running existing Linux kernel on an emulated PM around 14 USD was spent in the Linux stack, compared to only 8-9 USD in hardware – software slower than the hardware!
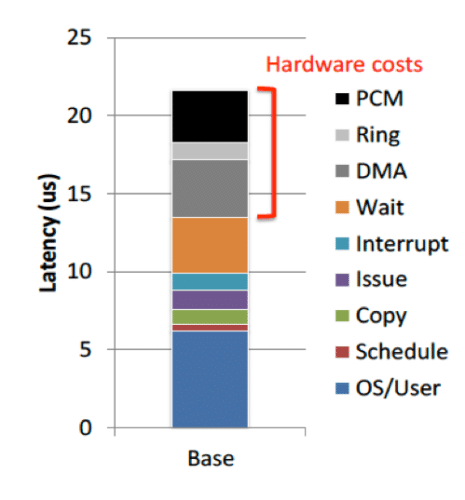 Here is the breakup. The culprit? Optimizations for hard disk drives or more recently solid-state drives. In the traditional world the access to persistent media is in units of blocks, which is 4096 bytes. However, PM is byte addressable. Moreover, the software layer introduces various optimizations to overcome slow drive speeds – for example, batching of I/O, caching the reads/writes in DRAM, converting random writes and/or reads to sequential and so on.
Here is the breakup. The culprit? Optimizations for hard disk drives or more recently solid-state drives. In the traditional world the access to persistent media is in units of blocks, which is 4096 bytes. However, PM is byte addressable. Moreover, the software layer introduces various optimizations to overcome slow drive speeds – for example, batching of I/O, caching the reads/writes in DRAM, converting random writes and/or reads to sequential and so on.
These become redundant and introduce overhead with the much faster, byte-addressable and random access persistent memory. It is not simple to disable or remove these optimizations since they are an integral part of software such as file systems and databases. Hence, there is a lot of research on determining how to optimally access data from NVM using existing software and how to build new ones.
But there are some challenges
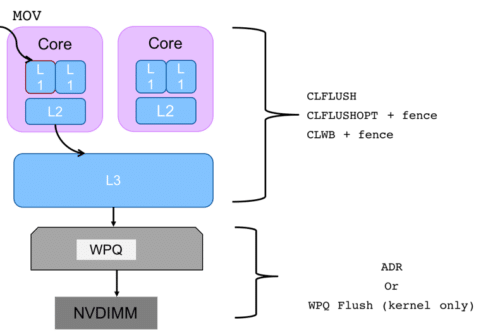 Moreover, there are a few roadblocks to persistence. Like writes in DRAM, when something is written to a memory location in persistent memory through a MOV instruction, it does not necessarily go to the durable media right away. This is because the data written to the memory location could be present in one or more of the CPU caches (L1, L2) for faster access. Although, caches help improve the performance, they come in the way of persistence and ordering of writes.
Moreover, there are a few roadblocks to persistence. Like writes in DRAM, when something is written to a memory location in persistent memory through a MOV instruction, it does not necessarily go to the durable media right away. This is because the data written to the memory location could be present in one or more of the CPU caches (L1, L2) for faster access. Although, caches help improve the performance, they come in the way of persistence and ordering of writes.
For example, even if MOV instruction returns, it is not guaranteed that the data has made it to the NV-DIMM and there is always a chance data loss in case of a sudden power failure. Since the caches evict the data and persist to PM in any order, it would break transactions, which are strict in ordering (e.g., allocating a linked list node and then updating the address in the previous linked list node).
Existing Intel x86 instructions, such as, CLFLUSH and SFENCE instructions help flush CPU caches to PM and in a specific order. Intel has recently introduced faster and optimized version of CLFLUSH, called CLFLUSHOPT, which is more suitable to flush large buffers. CLWB is another variant to flush caches, but it does not invalidate the cache line. It only write backs modified data to memory or NVM. In order to ensure that the data in cache line is persisted and in order with other writes, one needs to use a combination of CLFLUSHOPT/CLWB and SFENCE or CLFLUSH. We will see later APIs application programmers can call to achieve this functionality.
Undergoing researches
To achieve optimal performance from NVM and be able to use its characteristics (byte addressable persistence), there is a lot of research and standard body initiatives that is active in this area. One such example is that of a specification named NVM Programming Model (NPM) [5] proposed by SNIA. NPM defines recommended behavior between various user space and operating system (OS) kernel components supporting NVM. The specification describes the various access or programming modes. It discusses the aspects of atomicity, durability, ordering, error handling, etc. with respect to NVM.
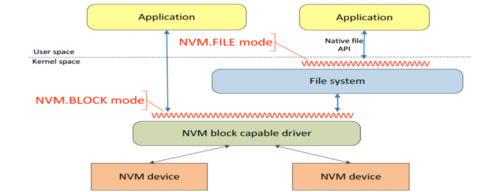 SNIA NPM proposes 4 programming models – NVM.BLOCK, NVM.FILE, NVM.VOLUME and NVM.PM.FILE. NVM.BLOCK and NVM.FILE modes are used when NVM devices provide a block storage abstraction and behavior to the software. NVM.BLOCK mode can be used by operating system components such as file system or used by applications that are aware of block storage characteristics. NVM.FILE mode can be used by existing applications written using native POSIX APIs such as open/read/write, etc. Moreover, NVM.FILE mode works with traditional block-based file systems such as ext3, ext4, XFS etc.
SNIA NPM proposes 4 programming models – NVM.BLOCK, NVM.FILE, NVM.VOLUME and NVM.PM.FILE. NVM.BLOCK and NVM.FILE modes are used when NVM devices provide a block storage abstraction and behavior to the software. NVM.BLOCK mode can be used by operating system components such as file system or used by applications that are aware of block storage characteristics. NVM.FILE mode can be used by existing applications written using native POSIX APIs such as open/read/write, etc. Moreover, NVM.FILE mode works with traditional block-based file systems such as ext3, ext4, XFS etc.
NVM.PM.VOLUME mode provides a software abstraction for persistent memory hardware – it provides a list of physical address ranges associated with each PM volume. This mode presents memory mapped capabilities so as to enable CPU load/store operations. NVM.PM.FILE is similar to NVM.FILE, with a few exceptions. This mode expects to use a PM-aware file system (not a block-oriented filesystem) that interacts with PM capable driver to discover or configure NVM. The PM-aware file system tries to get rid of all the optimizations for hard disks, which are present in traditional filesystems, as discussed earlier. It uses CPU load/store instructions to directly read/write data without involving any page or buffer cache. While the user application can use native POSIX calls to access files stored in NVM, it is recommended that the application memory maps the file and directly access the NVM media for better performance.
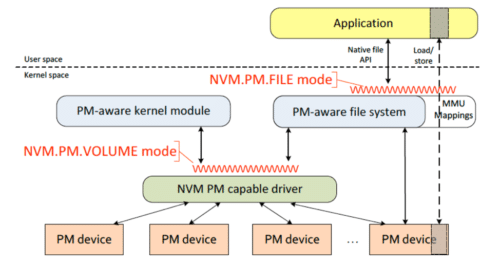
The behavior of NVM.PM.FILE differs from NVM.FILE once the application uses memory mapped I/O. This is because, in contrast to memory mapping a file to volatile DRAM from hard drive, we directly map the persistent memory to the user space with all stores (writes) being durable. This extension is represented by MMU Mapping in Figure 5. Since the data could be in the CPU caches, application needs to flush and fence based on the ordering and persistence requirement. The specification introduces new interfaces to achieve these objectives. For example, few interfaces specific to NVM.PM.FILE are:
” NVM.PM.FILE.MAP – Add a subset of a PM file to application’s address space for load/store access.
” NVM.PM.FILE.SYNC or NVM.PM.FILE.OPTIMZED_FLUSH – Synchronize persistent memory content to assure durability and enable recovery by forcing data to reach the persistence domain.
Based on SNIA NPM, Intel has developed a suite of userspace NVM Library (NVML) using memory-mapped persistence (pmem.io). The libpmem library of NVML provides low level persistent memory support at userspace, with key emphasis on flushing the changes to persistent memory. NVML provide many other high-level libraries built on top of libpmem. Some examples include libpmemlog, which provides a pmem-resident log and libpmemobj, which provides a transactional object store that provide memory allocation and transactions. Here is a small snippet of a program that uses NVML.
/* create a pmem file */
if ((fd = open(“/pmem-fs/myfile”, O_CREAT|O_RDWR, 0666)) < 0) {
perror(“open”);
exit(1);
}
/* allocate the pmem */
posix_fallocate(fd, 0, PMEM_LEN))
/* memory map it */
if ((pmemaddr = pmem_map(fd)) == NULL) {
perror(“pmem_map”);
exit(1);
}
/* store a string to the persistent memory */
strcpy(pmemaddr, “hello, persistent memory.”);
/* flush above strcpy to persistence */
pmem_flush(pmemaddr, PMEM_LEN);
pmem_drain();
strcpy(pmemaddr, “hello again, persistent memory.”);
pmem_persist(pmemaddr, PMEM_LEN);
The above code snippet, first creates a file on persistent memory of size PMEM_LEN – let’s call it /pmem-fs/myfile. This file is memory mapped using pmem_map call, which is a wrapper over mmap() system call. After some string is copied into the pmemaddr, we need to ensure that the string has indeed been persisted. Combination of pmem_flush() and pmem_drain() OR pmem_persist() ensure that the data is flushed all the way from the caches to the media. pmem_flush() and pmem_drain() internally call CLFLUSHOPT/CLWB and SFENCE, respectively. The code looks somewhat similar to what one would have done with a file stored on a hard drive and memory mapped to DRAM, except for a few differences: (a) the granularity of flush operation is much finer (byte level vs. block level/page level msync) and (b) the internal implementation of mmap is different, as discussed below.
NVML works on top of persistent memory aware file system or existing file systems with “Direct-Access” (DAX) support. Linux file systems such as ext4 and XFS and Windows 10 FS have added DAX [6,7] support which allows direct access to the NVM media i.e., bypassing the page cache and block layer. These file systems have an optimized version of mmap(), msync() and page fault handlers, for providing faster access to NVM. The memory map call, maps the physical NVM media directly to the userspace. This is contrary to memory mapping a file from hard disk – where a copy is maintained in the page cache (volatile memory) from the hard disk and the user application access this cached copy.
Thus, we see a lot of activity both in the user land and kernel space with respect to non-volatile memory. While I have just scratched the surface in this article, we could discuss in depth various software design aspects from NVM perspective such persistent memory file systems (e.g., PMFS, NOVA, etc.), remote access to NVM, transaction support, etc. NVM media definitely opens up a gamut of possibilities, which are still to be explored.
References:
[1] Phase Change Memory
[2] Resistive RAM
[3] Intel 3D XPoint
[4] A. Caulfield, A. De, J. Coburn, T. Mollov, R. Gupta, and S. Swanson. Moneta: A High-performance Storage Array Architecture for Next-generation, Non-volatile Memories. In Proceedings of the 43rd Annual IEEE/ACM International Symposium on Microarchitecture, 2010.
[5] SNIA NVM Programming Model
[6] Linux DAX
[7] Windows DAX