


 Speech Recognition is an important user interface enhancement for a variety of devices, ranging from smartphones, voice-controlled entertainment devices in the living room to hands-free conversing in automobiles. The idea behind speech recognition is to provide a means to transcribe spoken phrases into written text. Such a system has many versatile capabilities.
Speech Recognition is an important user interface enhancement for a variety of devices, ranging from smartphones, voice-controlled entertainment devices in the living room to hands-free conversing in automobiles. The idea behind speech recognition is to provide a means to transcribe spoken phrases into written text. Such a system has many versatile capabilities.
From controlling home appliances as well as light and heating in a home automation system, where only certain commands and keywords need to be recognized, to full speech transcription for note keeping or dictation. Imagine a humanoid which can interact with you. It is surprising, right?
In this article, we present a humanoid based on Raspberry Pi which can hear, see and speak. Yes! It can resemble a friend talking to you and performing some operations which you convey him to do. It takes input from you through speech and recognizes what you’ve spoken and performed certain intelligent tasks. It can interact orally with specific voice commands uttered by the user through a headphone or speaker connected to its audio jack.

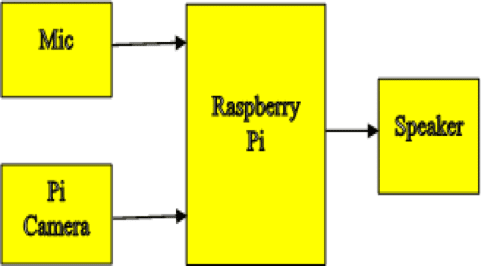
Figure 1: Block diagram
Block diagram and working
The block diagram consists of a Raspberry Pi, Microphone, Speaker and a Pi Camera module as shown in Figure 1. This provides three senses of intelligence. A user can make his work done by just speaking to the humanoid. This entire module can be placed in a humanoid and user can give a command to humanoid through speech which is recognized by Raspberry Pi and performs the necessary operation.
When the user speaks the predefined command, the microphone detects the voice and sends it to Raspberry Pi. Then raspberry pi detects the uttered command using pocketsphinx and performs necessary actions which are defined in the shell script (attached below).
Software
Before you follow with the software installations, ensure that your Raspberry Pi is already setup with Raspbian ‘wheezy’ operating system. You can refer ‘Getting Started with Raspberry Pi’ to set up the Raspberry Pi. Now all you need is a network connection on Raspberry Pi to install all the software. Refer ‘Set up Network for Raspberry Pi’ published in May 2013 issue for getting the network connection up on your Raspberry Pi. Once done, you can either connect a keyboard and a display to Raspberry Pi and start following the installations using Lx Terminal or you can access Raspberry Pi remotely using SSH and execute all the commands directly.
Software Installation
Update and upgrade Raspi-related software using the commands below and reboot your Raspberry pi.
$ sudo apt-get update
$ sudo apt-get upgrade
Initially you need to setup and properly configure alsa, then you can just build and run pocketsphinx
$ sudo apt-get update
$ sudo apt-get upgrade
$ cat /proc/asound/cards
Check your microphone is visible or not and if on, note the USB extension of it.
$ sudo nano /etc/modprobe.d/alsa-base.conf
If you want to receive output through 3.5mm jack then don’t alter any line. Otherwise change following line
# Keep snd-usb-audio from being loaded as first soundcard
options snd-usb-audio index=-2
To,
options snd-usb-audio index=0
Continue with following steps
$ sudo reboot
$ cat /proc/asound/cards
Check whether your device is at 0.
$ sudo apt-get install bison
$ sudo apt-get install libasound2-dev
Download Sphinx latest version and extract the files as below,
$ wget http://sourceforge.net/projects/cmusphinx/files/sphinxbase/0.8/sphinxbase-0.8.tar.gz/download
$ mv download sphinxbase-0.8.tar.gz
$ tar -xzvf sphinxbase-0.8.tar.gz
./configure –enable-fixed
$ make
$ sudo make install
Download Pocketsphinx latest version and extract the files as below,
$ wget http://sourceforge.net/projects/cmusphinx/files/pocketsphinx/0.8/pocketsphinx-0.8.tar.gz/download
$ mv download pocketsphinx-0.8.tar.gz
$ tar -xzvf pocketsphinx-0.8.tar.gz
./configure
$ make
$ sudo make install
Run the pocketsphinx to check it,
$ ./pocketsphinx_continuous –samprate 16000/8000/48000
The Pocketsphinx provides the tools for building language model by providing corpus database as shown in Table 1. The trained models are then used for the task of recognition. The recognized speech commands are used to do tasks or control a humanoid. Speech synthesis is implemented for necessary interaction between machine and human which allows machine to speak. Initially, the necessary commands are built in a text file (corpus). This text file is used to train the language model. Go to the page. Click on the Browse button; select the corpus.txt file created in the previous step, then click COMPILE KNOWLEDGE BASE.
A page with some status messages will appear, followed by a page entitled Sphinx knowledge base. This page will contain links entitled Dictionary and Language Model. Download these files and make a note of their names (they should consist of a 4-digit number followed by the extensions .dic and .lm). Now the language model can be tested with Pocketsphinx with the following command.
./pocketsphinx continuous -lm 0092.lm -dict 0092.dic
Here 0092 is the number obtained for our model. It will be usually different for different models. A lot of diagnostic messages appear, followed by a pause, then READY. At this stage, commands can be uttered. It should be able to recognize them with reasonably good accuracy.
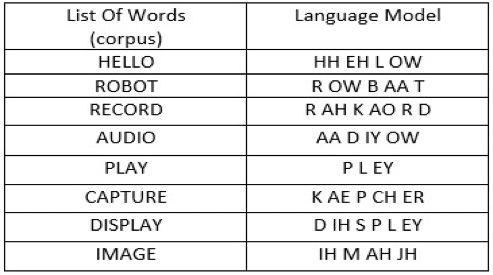
Table 1: language model for few words
Install some necessary packages on Raspberry Pi for Displaying an image and Speech synthesis (Text to Speech). The Festival Speech Synthesis System is a general-purpose multi-lingual speech synthesis system used here. Install Festival Text to Speech by using following commands in LX terminal.
$ sudo apt-get install links2
$ sudo apt-get install mplayer
$ sudo apt-get install festival
$ echo “Hello Robot, How do you do?” | festival
The RPi speaks out “Hello Robot, How do you do?” through speaker connected to the audio jack.
Please find the working code (opti.sh) below–
Copy the shell script to the path:- pocketsphinx-0.8/src/programs/
Shell script (opti.sh)
while [ 0 ]
do
timeout 15 ./pocketsphinx_continuous -adcdev plughw:1 -lm 0092.lm -dict 0092.dic | tee cmd.txt
#run pocketsphinx with your language model file and dictionary file name
head -n 4 cmd.txt | tail -n 1 > cmd1.txt
cut -d ” ” -f 2- cmd1.txt | tee cmd2.txt
case $(tr -d ‘ ‘ <cmd2.txt) in
HELLOROBOT) echo “Hello Everyone, Have a nice day” | –tts ;;
RECORDAUDIO) timeout 10 arecord –D plughw:1,0 sound.wav ;;
#record audio for 10 seconds
PLAYAUDIO) aplay sound.wav ;; #plaing the recorded audio
CAPUTREIMAGE) raspistill –o image.jpg ;; #captures the image file in .jpg format
DISPLAYIMAGE) links2 -g image.jpg ;; #display the image file named image.jpg
*) ;;
esac
done
