




The immense pace at which the technology is witnessing advancements is also pushing both the software and hardware developers to implement these changes to remain in sync with time. Let us find out how that is shaping the future of cameras, audio applications, and IoT devices
Today we have a great variety of multimedia applications, including applications for audio processing, speech recognition, automatic machine translation, text-to-speech, speaker recognition, and authentication. We also have image classification, object (face, person) detection, and semantic segmentation for imaging prospects.

These images require a lot of computation to enhance image quality. This can be done with a wide array of products, such as mobile devices, automotives, wearables, and the Internet of Things (IoT). A lot of this can also be done using edge devices but often we tend to offload a lot of the computing into the cloud and data centers.
Spectrum of Compute Engines for Multimedia
There are many options available at hand today. These are various computing engines (see Fig. 1) where you have varying degrees of energy efficiency and flexibility.
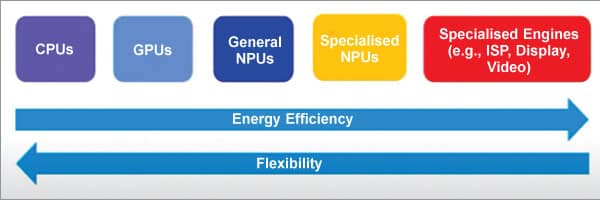
The left-most side in Fig. 1 has the lowest energy efficiency but with higher flexibility. There are central processing units (CPUs), graphics processing units (GPUs), general neural processing units (NPUs), and specialized NPUs that can take on various types of nn workloads, and then you can also go for a higher level of energy efficiency with specialized engines.
The right-most side engine can process a significantly larger amount of data with the highest efficiency. It comes at a trade-off for the least amount of flexibility.
Specialized Engines for High Efficiency
The following are some examples of specialized engines.
Let us take a look at an image signal processor (ISP) as a starting point for cameras. It takes in the raw input from the sensor with the data rate, for instance, 12MP @ 60 frames per second (fps)+108MP @ 15 fps. A lot of times the 15fps images are fused to form a high-quality image. Once the raw data is taken, it generates the final enhanced YUV images. You can perform image restoration along the way such as white balancing, lens shading correction, color correction, gamma correction, and tone mapping. It can either be local or global. There are also options for denoising, sharpening, and scaling.
Then there is a video encoder and decoder (for instance, 1080P @ 30fps or 4k @ 60fps). A lot of the time they allow you to capture videos and encode them in the compressed stream or you can playback the compressed video and show it for display. They typically support multiple formats as shown and they are also highly versatile in the sense that they can do both decoding as well as encoding and support multiple formats.
The display engine scales and mixes multiple sources and then perform some quality enhancements, such as toe mapping and various other corrections. It also does color space convergence to render the final image, and these types of specialized engines have the same characteristics, such as high energy efficiency.
So let us now look at some of the characteristics of these specialized engines.
Characteristics of Specialised Engines
All of them have a lot of processing as well as data movement involved. For instance, when there is a 12-megapixel being operated @ 60fps, it has a lot of pixels to process. To have high energy efficiency we try to avoid going to memory (DRAM). Many a time we try to do in-stream processing to save the energy that it takes to move the data around.
There are lots of registers that allow you to configure how the data is being processed but they do not have a lot of instructions to fetch and decode, such as the paradigm that you have in CPUs and GPUs. So, its programmability is limited, allowing you to gain a lot of energy efficiency.
Another characteristic is that they rely on classical approaches rather than newly developed deep learning-based approaches. Thus, they also have somewhat simpler computing. In a lot of cases if a problem has a closed-form solution, a classified configurable approach is the right approach.
Beyond Classical Approaches: Applications and Compute Requirements
Camera applications
These applications consist of two important steps: image understanding and image enhancement. For instance, Google Clip allows you to recognize a scene so you can use that to perform a capture decision.
The image enhancement based on the data or metadata that you have captured will let you take various approaches, such as getting a higher dynamic range or improving the resolution via multi-frame processing. You can do a bokeh effect by using single or multiple cameras. You can also do some adaptive scene control to have the right look and feel for the images you capture.
Let us take a look at the detection side of things now.
Intelligent camera
We often try to detect the location of the objects with this camera as well the scenes themselves. A lot of times we try to get an object or a scene for which we can adaptively automatically configure the data to get the best image quality.
If you combine ISP with machine learning (ML) acceleration, it opens the door for you to do a plethora of things, such as scene detection as well as image quality enhancement using the captured metadata.
Pixel Processing
Segmentation and single camera bokeh
You can apply the segmentation algorithm to a person and the background and then you can blur the background way more than the foreground using the segmentation map. It is important to note that at every pixel we need to make a classification for the foreground and background.
Semantic segmentation
This algorithm determines different parts in the image itself, such as skin, hair, trees, grass, and other aspects of a picture. This allows us to figure out the part of the image that is of interest. It is important to note that we are doing this classification at every pixel.
| Audio/speech/voice applications |
| A lot of the time a computer is offloaded to a small machine-learning accelerator to have high energy efficiency. There is often a tighter energy bound than the camera applications as well. |
Content-aware image enhancement
Once you have the mentioned semantic segmentation map for an image, you can enhance the color of things easily.
Shadow removal
Often you are in a backlit situation or where you are wearing a hat that casts a shadow on your face. This can be removed by simply applying some deep learning-based approaches. It is also important to keep in mind that we are trying to change the pixel value at every pixel, which requires a lot of computing.
Dehazing
Sometimes we have images that are quite hazy and foggy. To tackle that we can use some of the new state-of-the-art techniques where the conventional approaches do not work very well. If you look at the state of the art, you will see that a lot of the time it is dominated by deep learning-based approaches only.
Comparison of Compute Requirements
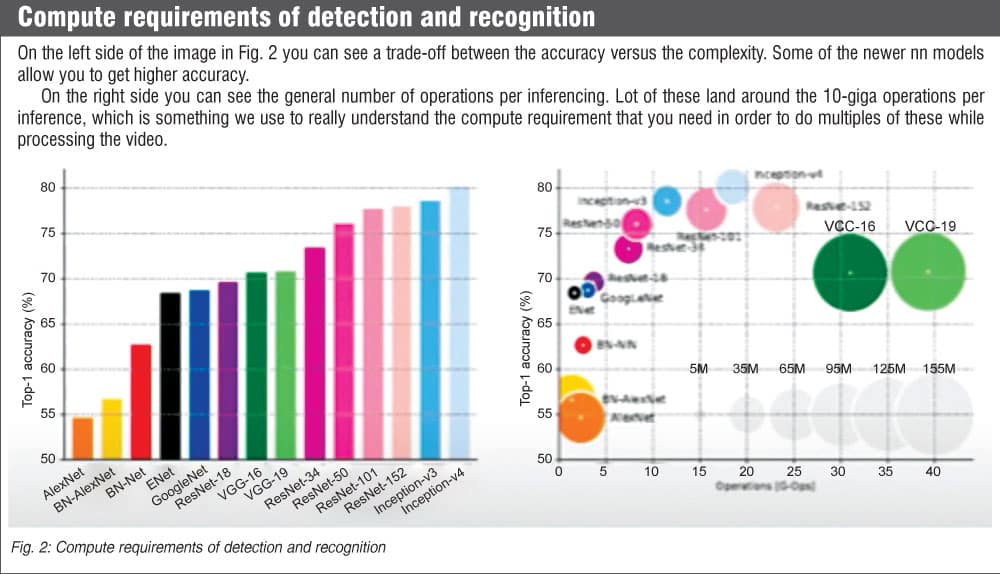
If you look at the detection/classification that is denoted by the yellow dots in Fig. 3, the x-axis is the log of giga operations per second. The blue dots are for image processing where you would either need to change the pixel values or you would need to do some classification at every pixel.
The amount of compute that you would need for those image-processing techniques can be seen. The blue dots cluster and yellow dots cluster are well separated. There is a huge gap between detection/classification versus image processing.
Let us take a look at Fig. 4 where the green dots are a reference for speech and audio. In all the deep learning-based approaches you can find a huge gap in the compute requirement. There are about six to seven orders of magnitude differences between the green dots and the blue dots.
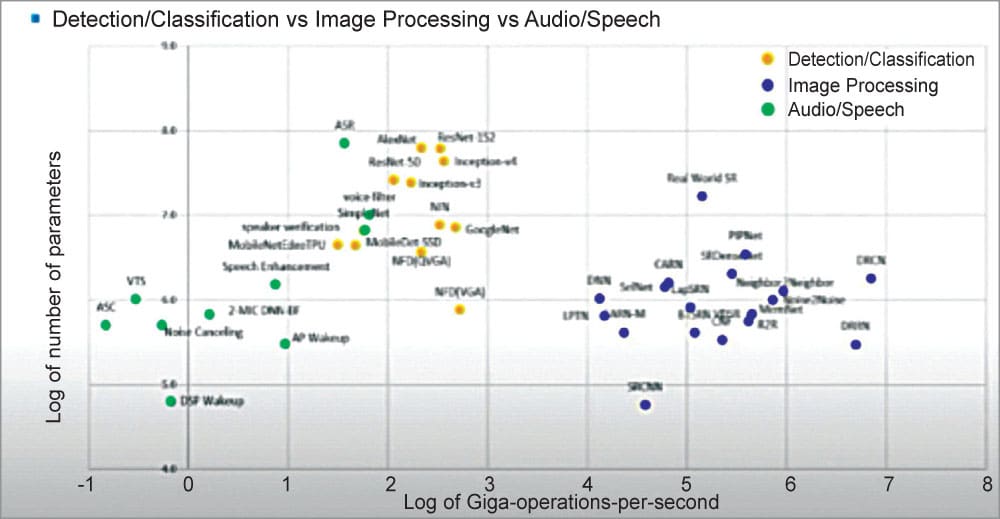
To summarise, it is important to understand that many multimedia applications require a lot of compute and data movement for which classical approaches are often used for higher efficiency in specialized engines. If a problem has a closed-form solution then you should use the classical configurable approach. Ill posed problems may deploy DL-based algorithms for high quality. Deep learning-based approaches vary in compute complexity by five to seven orders of magnitude and fine-grained domain-specific processors are used for diverse workloads.
This article is based on a tech talk at VLSI 2022 by Suk Hwan Lim, Executive Vice President, Head of America S.LSI R&D Center, Samsung. It has been transcribed and curated by Laveesh Kocher, a tech enthusiast at EFY with a knack for open-source exploration and research.
