




Neural networks, AI, ML, and neuromorphic computing are technologies that are actually ways to make machines behave more like humans! Similarly, computer vision focuses on imitating the complex human vision system and leveraging it in applications
Computer vision is a type of artificial intelligence (AI). The aim is to make computers visualise and understand images or videos as humans do. The field has grown a lot over the last decade, especially due to the new hardware and algorithms that came into the picture. Not just that, this type of computation has become faster and more accessible since the amount of data that is generated has also increased. Thanks to improved training models, deep learning, and better hardware, we are able to identify objects more accurately today.

 Computer vision works by recognising patterns in images and videos. You feed the computer with an image of a particular object and then make the computer analyse it using algorithms—the borders, colours, shades, and shapes. We are essentially training a computer to understand and interpret the world.
Computer vision works by recognising patterns in images and videos. You feed the computer with an image of a particular object and then make the computer analyse it using algorithms—the borders, colours, shades, and shapes. We are essentially training a computer to understand and interpret the world.
Computer vision: Then and now
In his whitepaper titled ‘Everything You Ever Wanted To Know About Computer Vision,’ Ilija Mihajlovic, an iOS developer who is passionate about machine learning (ML), explains how ML and deep learning have simplified computer vision. Before deep learning came into the picture, computer vision did not have as much scope as it does today, mainly because a lot of manual coding was required, such as creating a database, annotating images, capturing new images, etc.
“With machine learning, developers no longer needed to manually code every single rule into their vision applications. Instead, they program features or smaller applications that could detect specific patterns in images,” writes Mihajlovic. Today, we use deep learning for computer vision, and all of the work is done by neural networks. When we provide neural networks with lots and lots of labeled images of a particular object, they are able to identify patterns in them.

Hardware for computer vision
Capturing data is an important aspect of computer vision applications, and hardware platforms play a major role here. The main components required for computer vision applications are cameras and image sensors for capturing images, I/Os, a communication interface, and a processing unit. Imaging sensors present in cameras are characterised by their resolution (number of pixels), speed (frames per second), and number of colours.
Depending on the type of computer vision application, the processing unit might vary from CPUs to embedded boards. Here are a few examples:
- CPUs
- GPUs
- Heterogenous systems (CPUs +GPUs+others)
- FPGAs
- ASICs
- Microcontroller boards
- Embedded systems (smart cameras)
 So where do development boards stand?
So where do development boards stand?
Traditional computer vision systems used a camera connected to a general-purpose computer, which used to run the application. In a smart camera though, the whole system can be integrated, right from capturing the image to processing to the final application. Today, the distinction between smart cameras and development boards has slowly started to fade, since many development boards have inbuilt cameras and are tailored for computer vision applications.
With more and more applications being deployed on edge, it makes more sense to deploy such devices on development boards. Here are some critical features that you need to consider while selecting a development board for your computer vision application:
- High processing speed
- Edge processing ability
- Faster access to memory
- Low power consumption
- Portable
- Inexpensive
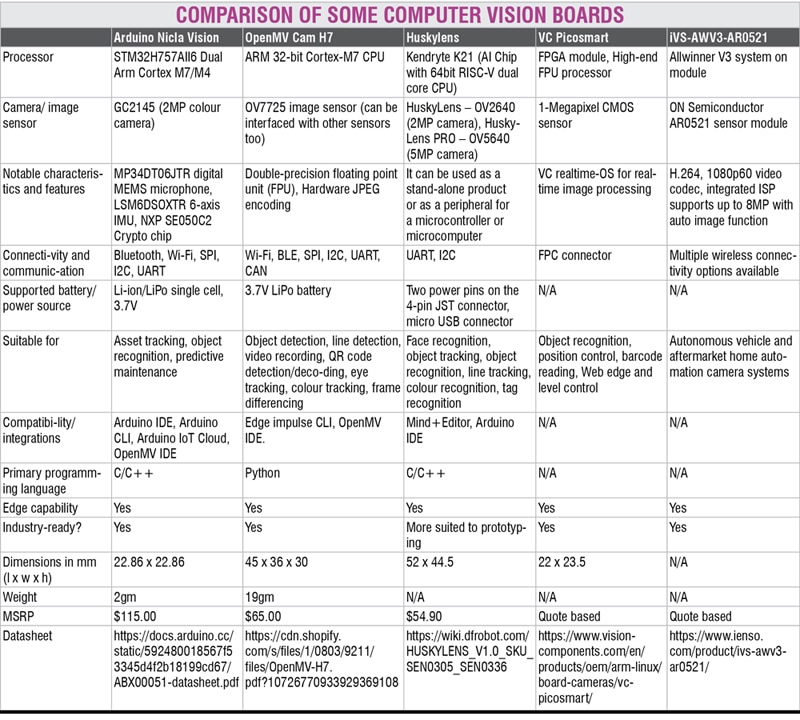
While there are embedded platforms specifically for AI like NVIDIA Jetson and Raspberry Pi Compute, AI accelerators like Google TPU, SOMs/SBCs containing high-quality imaging sensors, we will focus on a few boards that were designed for computer vision and compare some of their features.
Current trends in computer vision
Computer vision on edge
To successfully deploy computer vision on edge, neural network design must be integrated into embedded platforms. Then, there are also difficult design decisions to be made around power consumption, cost, accuracy, and flexibility. Overall, for bandwidth, speed, and security reasons, edge computing is critical to computer vision processes. Still, hackers could take advantage of emerging security flaws in artificial intelligence. Designers must take this into consideration too.

However, there are some challenges when it comes to vision AI on edge, such as involving all edge endpoints can lead to complex device architectures. This makes device management and edge computing implementation harder. Edge computing differs from cloud architecture as it is spread out rather than centered around a single cloud. For large enterprises, it may be assumed that such an infrastructure will have higher maintenance costs than one centered upon the cloud.
Embedded vision and IoT embedded vision
Embedded vision is when we combine cameras with the processing unit, like smart cameras mentioned before. Many companies, like Lattice Semiconductor and Blaser AG, provide embedded vision solutions. For example, Basler’s AI Vision Solution Kit comes with cloud connectivity and contains a dart MIPI camera module, an NVIDIA Jetson Nano development board, lens, and cable. It allows developers to test AI based IoT applications on an optimised vision system and to access cloud services.
But we are about to enter the next stage of the Internet of Things. So far, the focus was on connecting devices, accumulating data, and creating big data platforms. Now, our focus will move to making the ‘things’ smarter using technologies like computer vision and deep learning on edge. This way, the things will be able to make informed decisions about their surroundings. That’s IoT embedded vision.
Vision processing units (VPUs)
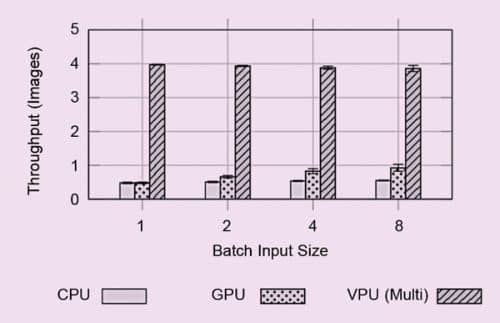
A VPU is a specific type of AI accelerator designed for computer vision tasks. It is well suited for parallel processing. A very popular edge AI accelerator is the Intel Neural Compute Stick 2, which is built on the Myriad X VPU. It offers an easy-to-use USB interface.
Pre-trained convolutional network (CNN) models are used in the VPU chips to execute inference tasks. Studies have shown that VPUs are superior to CPUs and GPUs in terms of performance as well as power consumption. Moreover, a combination of multiple VPU chips can even reduce the thermal-design power (TDP) by up to eight times.
Software 2.0 and computer vision
As we move towards Industry 4.0, software development is also moving towards Software 2.0. Software 1.0—the technology stack that includes languages like C/C++, python, etc—is the one that we are familiar with. It needs a coder. On the other hand, Software 2.0 literally writes itself when we feed enough data to a neural network that knows how to code.
This is yet another reason why the computer vision market will continue to grow exponentially. It will drive Software 2.0. Andrej Karpathy, Director of AI at Tesla, is a big proponent of Software 2.0. He notes that with Software 2.0, the computer vision library (for example, OpenCV) could even be auto-tuned on our specific data!
The author, Aaryaa Padhyegurjar, is an Industry 4.0 enthusiast at EFY with a keen interest in innovation and research.

