




AUGUST 2012: While surfing the Internet, many a times you need to create accounts on different Web domains and fill in some online forms. During registration process or on entering the wrong password while logging into an account, you encounter a code containing blurry or distorted letters. You are prompted to enter these distorted characters in a textbox. The registration or login is allowed only if you correctly enter this code in the textbox.

To most of us, this requirement appears just as a hindrance. But have you ever thought what exactly are these simple tests for, and is there any significance of their use?
To give you an introduction, this is actually one of the Web testing mechanisms referred to as CAPTCHA. The term CAPTCHA, an acronym for ‘Completely Automated Public Turing Test to Tell Computers and Humans Apart,’ was coined in 2000 by Louis von Ahn, Nicholas Hopper and John Langford of Carnegie Mellon University.
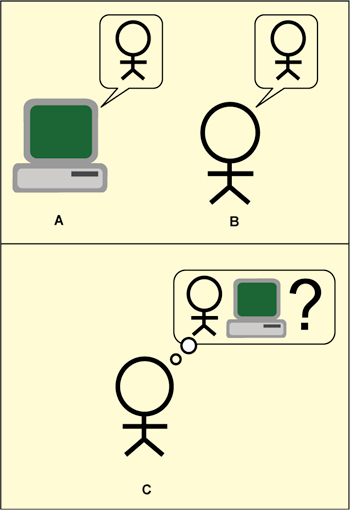
CAPTCHA has its foundation in an experiment called Turing test. The Turing test is a test of a machine’s ability to exhibit intelligent behaviour. The classic Turing test is a game of imitation comprising an interrogator and two participants, of which one is a human and the other a machine (see Fig. 1). The interrogator sits in one room and the participants are made to sit in different rooms. The setup is such that the participants are not visible to the interrogator.

The interrogator asks both the participants some questions and from their responses tries to distinguish between the human and the machine. If the interrogator is unable to distinguish, the machine passes the Turing test.
CAPTCHA is basically a type of challenge-response test used in computing as an attempt to ensure that the response is generated by a human. The tests are designed such that humans could easily pass them but not the machine. Thus the test identifies which users are actually real human beings and which are automated programs. It is also referred to as reverse Turing test as it is administered by a machine and targeted at humans.
This raises the question “why the CAPTCHA was introduced?” The reason is that there may be someone trying to infiltrate your services by using automated programs (bots) to access the Internet, affecting a large number of users in their daily work. For example, e-mail service might itself be bombarded by requests from an automated system sending spam mails over the servers. So CAPTCHA here identifies between the requests from human beings and automated programs and prevents the access to these automated programs.
How CAPTCHA works
In general, first of all, a random value is created as random values are often hard to guess and predict. Then an image is generated, as visual data is quite hard to process by the computers but provides ease of readability to the human beings. The developer employs a high level of complexity so that the image cannot be cracked. This generated text image is then stored.
Later, the user is asked to enter CAPTCHA. If the entered CAPTCHA matches with the stored CAPTCHA, the user is allowed to access, login or submit the form. This is well illustrated in Fig. 2.

Areas of use
There are lots of areas in which CAPTCHA is currently used. These include protecting website registration, protecting e-mail addresses from scrappers, preventing automated programs from corrupting online polls, preventing comment spam in blogs, and preventing search engine bots from reading webpages.
CAPTCHA is undoubtedly a very reliable test in most Web applications. The developers are continuously working to take this very gift of artificial intelligence to new levels, leaving bots far behind.

