Globally, there will be over 20 billion connected devices in the next five years, representing $7 trillion dollars in revenue. This corresponds to roughly three devices for every person and a value higher than the year 2016 GDP of all the countries in the world, except the US and China. Many of these systems including implantables, wearables, printed electronics and the Internet of Things (IoT) will have ultra-low power and area requirements. So these applications will rely on ultra-low-power general-purpose microcontrollers and microprocessors, making them the most abundant type of processors produced and used.
Two types of processors are available at present: Commercial-off-the-shelf (COTS) and bespoke. The two have many similar features, such as a pipeline and cache.

Specifically, COTS processors satisfy needs of the purchasing organisation without the need to commission custom made, or bespoke, solutions. Compared to custom processors, these are cheap, flexible (avoid binding solution to a single hardware/software source) and backward-compatible with legacy products. These provide current technology solutions and shorten design-to-production cycles, with their large user base generally uncovering design defects early.
While COTS processors are likely to be built for optimal average case performance, bespoke processors are designed to ease the certification process. Typical types of evidence required for certification are worst-case execution time of instructions, hardware reliability and information on systematic design flaws in the processor.

Bespoke processors are used for applications with ultra-low area and power constraints. Low-power processors are widely used and are expected to power a large number of emerging applications. Such processors tend to be simple, run relatively simple applications, and do not support non-determinism, which makes symbolic simulation-based technique a good fit for such processors.
Power and area efficiency concerns
Microprocessors and microcontrollers used in the emerging area- and power-constrained connected applications are designed to include a wide variety of functionalities in order to support a large number of diverse applications with different requirements. On the other hand, the embedded system is designed for typically a small number of applications, running over and again on a general-purpose processor for the lifetime of the system. Given that a particular application may only use a small subset of the functionalities provided by a general-purpose processor, there may be a considerable amount of logic in the processor that is not used by the application.
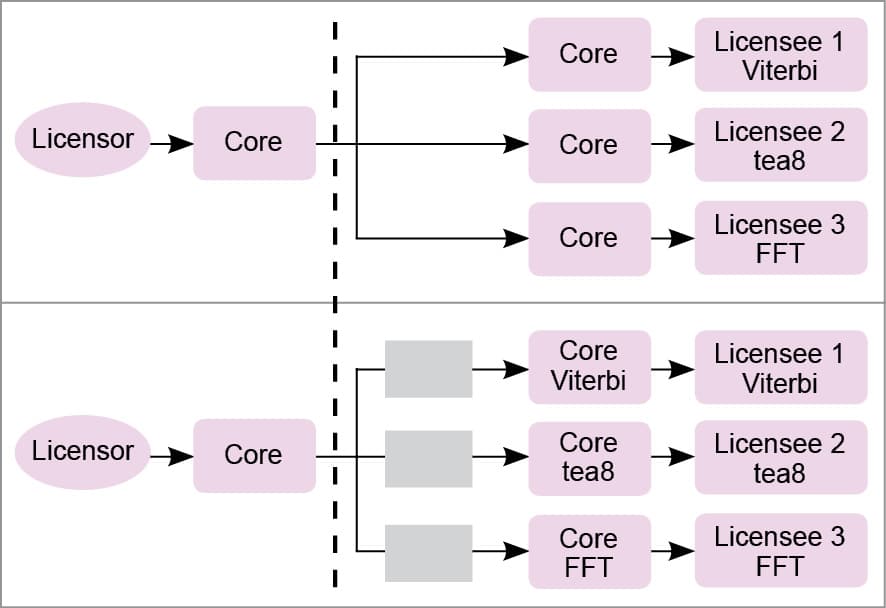
Cost concerns drive many of the connected applications to use general-purpose microprocessors and microcontrollers instead of much more area- and power-efficient ASICs, as, among other benefits, development cost of microprocessor IP cores can be amortised by the IP core licensor over a large number of chip makers and licensees. Given the mismatch between the extreme area and power constraints of emerging applications and the relative inefficiency of general-purpose microprocessors and microcontrollers compared to their ASIC counterparts, there exists a considerable opportunity to make microprocessor-based solutions for these applications much more area- and power-efficient.
One big source of area inefficiency in a microprocessor is that a general-purpose microprocessor is designed to target an arbitrary application and thus contains many more gates than what a specific application needs. The unused gates continue to consume power, resulting in significant power inefficiency, too. While adaptive power management techniques help to reduce power consumed by unused gates, the effectiveness of such techniques is limited due to the coarse granularity at which these must be applied, as well as significant implementation overheads such as domain isolation and state retention. These techniques also worsen area inefficiency.
Approaches
One approach to significantly increase the area and power efficiency of a microprocessor for a given application is to eliminate all logic in the microprocessor IP core that will not be used by the application. Eliminating logic that is not used by an application can produce a design tailored to the application—a bespoke processor—that has significantly lower area and power requirements than the original microprocessor IP that targets an arbitrary application.
As long as the approach to create a bespoke processor is automated, the resulting design retains the cost benefits of a microprocessor IP, since no additional hardware or software needs to be developed. Also, since no logic used by the application is eliminated, area and power benefits come at no performance cost. The resulting bespoke processor does not require programmer intervention or hardware support either, since the software application can still run, unmodified, on the bespoke processor.
Static application analysis represents another approach for determining unusable logic for an application. However, application analysis may not identify the maximum amount of logic that can be removed, since unused logic does not correspond only to software-visible architectural functionalities but also to fine-grained and software-invisible micro-architectural functionalities.For example, consider two different applications: FFT and binSearch. Since these applications use different subsets of the functionalities provided by the processor, the parts of the processor that they do not exercise are different. However, a closer look reveals that while some of the differences correspond to coarse-grained software-visible functionalities, other differences are fine-grained, software-invisible, and cannot be determined through application analysis.
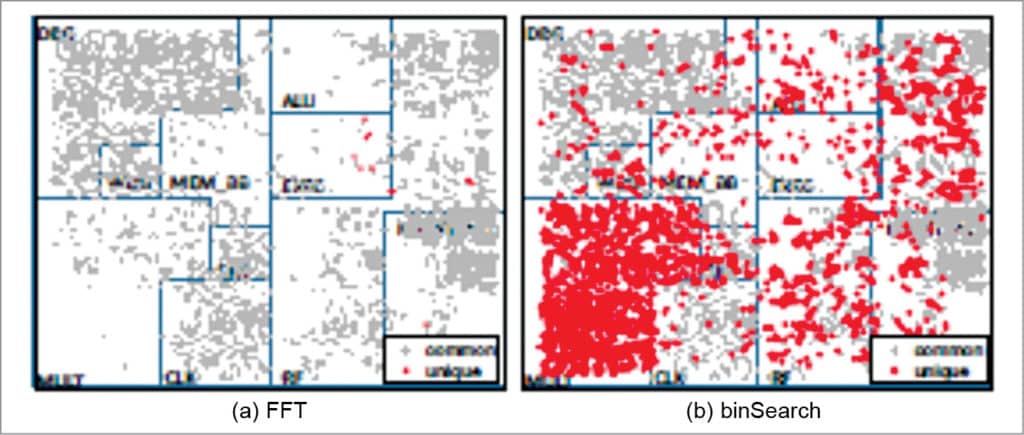
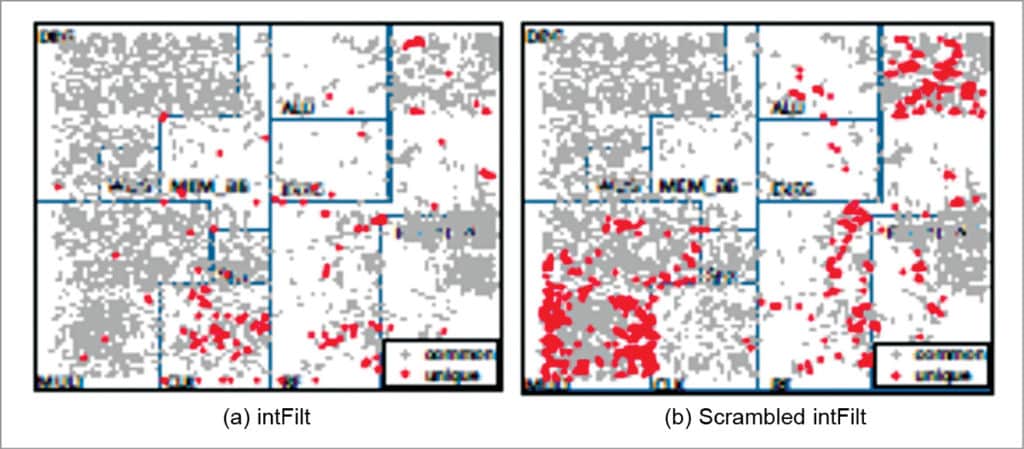
The two applications use exactly the same instructions; however, die graphs in Figs 2 and 3 show that the sets of unexercised gates for the applications are different. This is due to the fact that even the sequence of instructions executed by an application can influence which logic the application can exercise in a processor depending on the micro-architectural details. Such interactions cannot be determined simply through application analysis.
Given that the fraction of logic in a processor that is not used by a given application can be substantial, and many area- and power-constrained systems only execute one or few applications for their entire lifetime, it may be possible to significantly reduce area and power in such systems by removing logic from the processor that cannot be used by the applications. However, since different applications can exercise substantially different parts of a processor, and simply profiling or statically analysing an application cannot guarantee which parts of the processor can and cannot be used by an application, tailoring a processor to an application requires a technique that can identify all the logic in a processor that is guaranteed to never be used by the application and remove unusable logic in a way that leaves the functionality of the processor unchanged for the application.
In the next section, we describe a methodology that meets these requirements. We call general-purpose processors that have been tailored to an individual application ‘bespoke processors’—reminiscent of bespoke clothing, in which a generic clothing item is tailored for an individual person.
Tailoring a bespoke processor to a target application
Bespoke processor design tailors a general-purpose processor IP to a target application by removing all gates from the design that can never be used by the application. The bespoke processor, tailored to the target application, must be functionally equivalent to the original processor when executing the application. It should retain all the gates from the original processor design that might be needed to execute the application.
Any gate that could be toggled by the application and propagate its toggle to a state element or output port performs a necessary function and must be retained to maintain functional equivalence. Conversely, any gate that can never be toggled by the application can safely be removed, as long as each fan-out location for the gate is fed with the gate’s constant output value for the application.
Removing constant gates for an application could result in significant area and power savings without any performance degradation. In addition, gate removal can expose additional timing slack, which can be exploited to increase area and power savings or performance of a bespoke design. On an average, bespoke processor design reduces area and power consumption by 62 per cent and 50 per cent, while exploiting exposed timing slack improves average power savings to 65 per cent.
The first step of tailoring a bespoke processor—input-independent gate activity analysis—performs a type of symbolic simulation, where unknown input values are represented as X’s, and gate-level activity of the processor is characterised for all possible executions of the application, for any possible inputs to the application.
The second phase of bespoke processor design technique—gate cutting and stitching—uses gate-level activity information gathered during gate activity analysis to prune away unnecessary gates and reconnect the cut connections between gates to maintain functional equivalence to the original design for the target application.
Input-independent gate activity analysis
The set of gates that an application toggles during execution can vary depending on application inputs. This is because inputs can change the control flow of execution through the code as well as data paths exercised by the instructions.
Since exhaustive profiling for all possible inputs is infeasible, and limited profiling may not identify all exercisable gates in a processor, the analysis technique is based on symbolic simulation. This technique is able to characterise the gate-level activity of a processor executing an application for all possible inputs with a single gate-level simulation. During this simulation, inputs are represented as unknown logic values (X’s), which are treated as both 1’s and 0’s when recording possible toggled gates.
Symbolic simulation has been applied in circuits for logic and timing verification, as well as sequential test generation. More recently, it has been applied in determination of application-specific Vmin. Symbolic simulation has also been applied for software verification. However, no existing technique seems to have applied symbolic simulation to create bespoke processors tailored to an application.
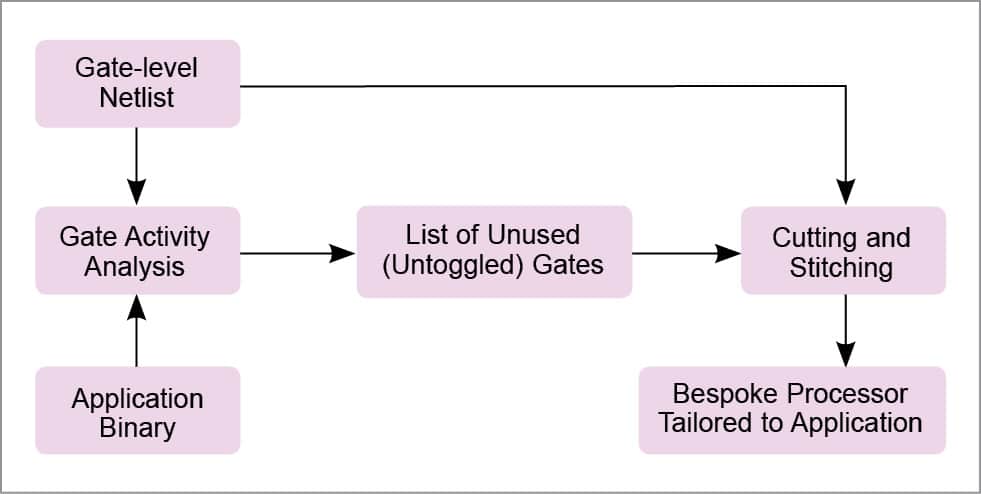
Initially, values of all memory cells and gates are set to X’s. The application binary is loaded into program memory, providing values that effectively constrain which gates can be toggled during execution. During simulation, the simulator sets all inputs to X’s, which propagate through the gate-level netlist during simulation.
After each cycle is simulated, toggled gates are removed from the list of unexercisable gates. Gates where an ‘X’ propagated are considered as toggled, since some input assignment could cause the gates to toggle. If an ‘X’ propagates to the PC, indicating input-dependent control flow, the simulator branches the execution tree and simulates execution for all possible branch paths, following depth-first ordering of the control flow graph.
This naive simulation approach does not scale well for complex or infinite control structures which result in a large number of branches to explore. So a conservative approximation could be employed that allows the analysis to scale for arbitrarily-complex control structures while conservatively maintaining correctness in identifying exercisable gates. The approximation works by tracking the most conservative gate-level state that has been observed for each PC-changing instruction. The most conservative state is the one where the most variables are assumed to be unknown (X).
When a branch is re-encountered while simulating on a control flow path, simulation down that path can be terminated if the symbolic state being simulated is a sub-state of the most conservative state previously observed at the branch, since the state (or a more conservative version) has already been explored. If the simulated state is not a sub-state of the most conservative observed state, the two states are merged to create a new conservative symbolic state by replacing differing state variables with X’s, and simulation continues from the conservative state. This conservative approximation technique allows gate activity analysis to complete in a small number of passes through the application code, even for applications with an exponentially-large or infinite number of execution paths.
The result of input-independent gate activity analysis for an application is a list of all gates that cannot be toggled in any execution of the application, along with their constant values. Since the logic functions performed by these gates are not necessary for the correct execution of the binary for any input, these may safely be cut from the netlist as long as their constant output values are preserved. The following section describes how unusable gates can be cut from the processor without affecting its functionality for the target application.
Cutting and stitching
Once gates that the target application cannot toggle are identified, these are cut from the processor netlist for the bespoke design. After cutting out a gate, the netlist must be stitched back together to generate the final netlist and laid-out design for the bespoke processor.
Fig. 5 shows the method for cutting and stitching a bespoke processor. First, each gate on the list of unusable gates is removed from the gate-level netlist. After removing a gate, all fan-out locations that were connected to its output net are tied to a static voltage (‘1’ or ‘0’) corresponding to the constant output value of the gate observed during simulation. Since logical structure of the netlist has changed, the netlist is re-synthesised after cutting all unusable gates to allow additional optimisations that reduce area and power.
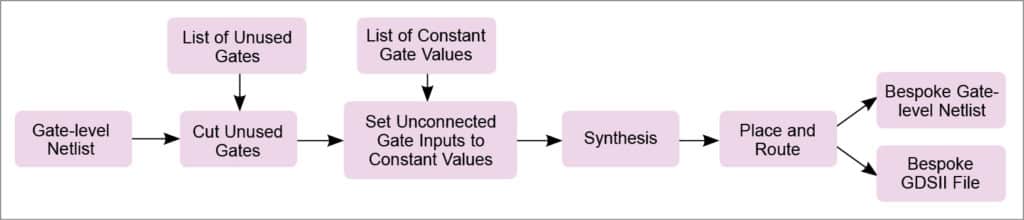
Gates having constant inputs after cutting and stitching can be replaced with simpler gates. Also, toggled gates left with floating outputs after cutting can be removed, as their outputs can never propagate to a state element or output port. Since cutting can reduce the depth of logic paths, some paths may have extra timing slack after cutting, allowing faster, higher-power cells to be replaced with smaller, lower-power versions of the cells. Finally, the re-synthesised netlist is placed and routed to produce the bespoke processor layout, as well as a final gate-level netlist with necessary buffers, etc to meet timing constraints.