




Fruit classification using a deep convolutional neural network (CNN) is one of the most promising applications in personal computer vision. Profound learning-based characterisations are making it possible to recognise fruits from pictures. However, fruit recognition is still a problem for the stacked fruits on a weighing scale because of the complexity and similarity.
In this article, a fruit recognition framework utilising CNN is proposed. The proposed strategy utilises profound learning methods for the grouping. The work uses the fruit shape and shading to recognise each picture.
We have used the Fruits-360 dataset for the evaluation purpose. An exact and dependable picture-based fruit recognition framework is crucial for supporting more significant rural assignments like yield mapping and automated reaping.

Introduction
These days, the process of mechanisation is playing a vital role in numerous businesses. Several programmed techniques are created for delivering and checking forms. The subject of computerised picture handling has found numerous applications in the field of mechanisation.
In personal computer vision and example acknowledgment, shape coordination is a significant issue, which is characterised as the foundation of shapes and its utilisation for shape examination. Fruit recognition and classification systems can be utilised by numerous genuine applications.

For example, a general store checkout framework may be used as an instructive device instead of manual scanner tags to upgrade learning, particularly for kids and Down’s syndrome disorder patients. It can help plant researchers to do an advanced examination on a variety of fruit shapes and assist in understanding the hereditary and sub-atomic instruments of the organic products.
Recognising various types of fruits is a rehashed task in grocery stores, where the clerk needs to characterise everything to decide the cost. A well-known answer for this trouble is to provide codes to every fruit item.
Along these lines, the main objective of this work is to program the perceived fruit picture by grouping it as indicated by its highlights utilising AI methods. An image recognition model is proposed, which contains three stages: pre-preparing, include extraction, and arrangement stages.
In include extraction stage, scale invariant feature transform (SIFT) and shape and shading calculations are used to extricate a component vector for each picture. The classification phase uses two algorithms: K-nearest neighbourhood (K-NN) and bolster vector machine (SVM). Assessing the recognition model is finished by completing a progression of trials. The after-effects of completing these examinations exhibit that the proposed approach can naturally arrange the fruit name with a high level of exactness.
Related work
TensorFlow
TensorFlow is an open source programming library for machine learning (ML) applications such as neural networks. It was developed by the Google Brain group for Google’s exploration and product advancement. It was released under the Apache license 2.0 on November 9, 2015. TensorFlow can run on several CPUs and GPUs in work area conditions. It is used in numerous fields such as voice acknowledgment, personal computer vision, mechanical technology, data recovery, and characteristic language handling.
CNN
Convolution neural network (CNN) is a class of deep learning that has accomplished creative outcomes in different fields such as natural language processing and image recognition. The layers of a CNN consist of an input layer, an output layer, and a hidden layer. The hidden layer includes multiple convolutional layers, pooling layers, fully-connected layers, and normalisation layers.
Inception-v3 model
The Inception-v3 model is a state-of-art image recognition model created by Google. It is the third edition of Google’s Inception Convolutional Neural Network, originally introduced during the ImageNet Recognition Challenge 2012. The Inception-v3 model comprises two sections: Highlight extraction part with a convolutional neural system and classification part with fully-connected and softmax layers.
Fruits-360 data set
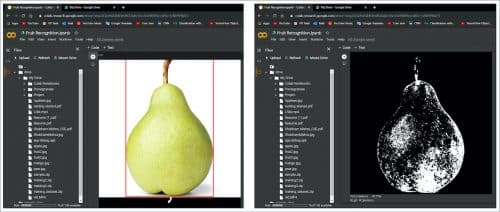
In this article, we have used the Fruits-360 dataset to identity fruits from pictures. For this, fruits were planted in the pole of a low-speed engine (3rpm), and a short film of 20 seconds was recorded. Behind the organic products, we set a white piece of paper as a background. Due to the variations in lighting conditions, the background was not uniform, and we composed a devoted calculation that separated fruits from the background.
This algorithm is flood-fill type: we start from each edge of the picture and mark all pixels there. At that point we mark all pixels found in the area of effectively checked pixels for whcih separation between hues is not exactly an endoresed esteem. We rehash the past advance until no more pixels can be checked. All checked pixels are considered as being background (which is then filled with white), and the remaining pixels are considered as belonging to the object.
The maximum value for the distance between two neighbouring pixels is a parameter of the calculation and is set (by experimentation) for every film. Fruits were scaled to fit a 100×100 pixel picture.
Proposed methodology
The framework takes a picture of the fruit with a camera, and the initial step runs a little neural system in TensorFlow to recognise whether the picture is a natural product (Fig. 1). The picture is then passed to the TensorFlow CNN neural system learning on a Linux server for additional grouping.
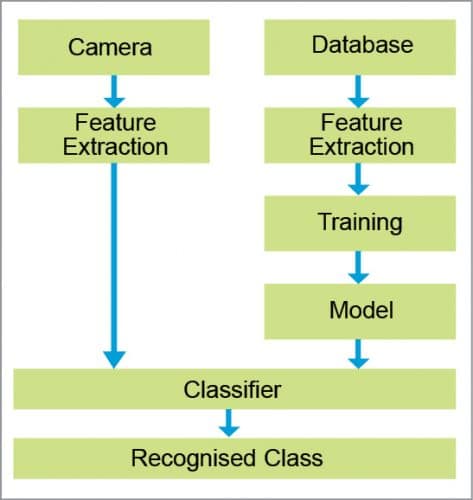
The TensorFlow code is an Inception-v3 model code given by Google that alters the union, pooling, and arrange configuration to coordinate the number of classes and classes of pixels in the picture with minor alterations to the last layer. CNN places a convolutional layer and a pooling layer in the concealed layer between the info and yield layers (Fig. 2).
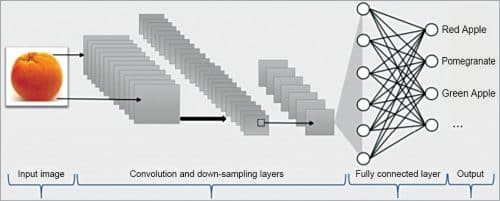
In these two layers, the way of bringing down or testing the goals of the picture is rehashed. The convolution layer applies a weighted channel to a piece of the information picture that might be useful for grouping, making an element map. The pooling layer decreases the element map by sub-testing the most significant piece of the component map received from the convolutional layer.
It reduces the size of the information while keeping up the attributes, subsequently forestalling the difference in the information because of the area change and improving the exhibition of the neural system by diminishing the information size. In light of these removed highlights, the grouping is performed.
Experimental analysis
To order the picture information, first, the folders are created with different names and the image data is stored corresponding to the folder name. Second, each picture information gathered is changed by the code of characterising fruits by the Google Inception-v3 model. Picture learning is completed. At last, in view of the finished retraining Inception-v3 model, the test continues.
Result
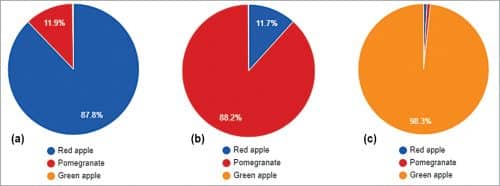
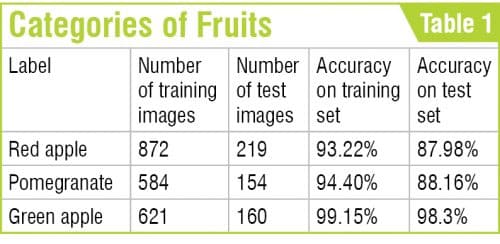
We did tests based on the Inception-v3 model, which was fixed. Test image information was gathered using red apple, pomegranate, and green apple.
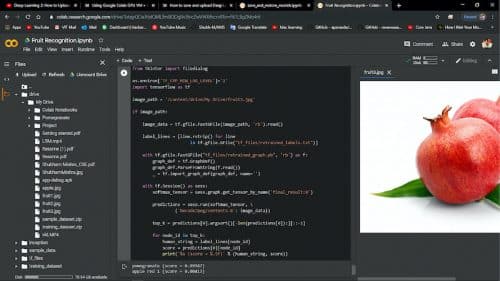
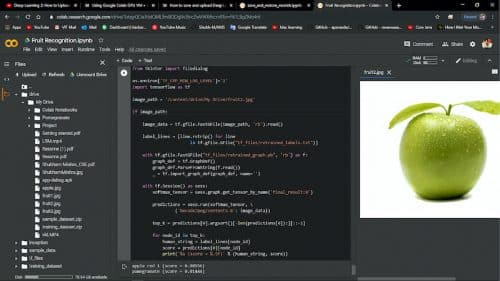
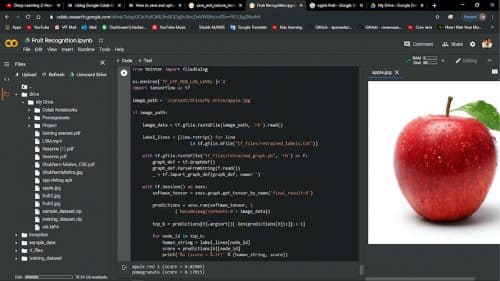
Because of the test, it was seen that red apple was grouped into 0.87959 per cent. Because of rehashed tests, it was affirmed that the more the quantity of preparing steps and picture information as per personal computer particulars, the higher the grouping precision. Later on, it will be important to develop a reason for high characterisation exactness by expanding the particulars of the exploratory personal computer and gathering more picture information.
Conclusion
This undertaking attempts to start an area that is less explored at present. During this project, we had the option to investigate some portion of the profound learning algorithms and find qualities and shortcomings. We picked up information on deep learning, and we got a product that can perceive fruits from pictures.
We trust that the outcomes and strategies introduced in this article can be additionally extended to a greater task. From our perspective, one of the principal goals is to improve the precision of the neural system. This includes further exploring different avenues regarding the structure of the system.
Another alternative is to supplant all layers with convolutional layers. This appears to give some improvement over the systems that have completely associated layers in their structure.
A result of supplanting all layers with convolutional ones is that there will be an expansion in the number of parameters for the system. Another chance is to replace the corrected straight units with exponential direct units. We might want to evaluate these practices and attempt to discover new arrangements that give fascinating outcomes. Soon we can make a portable application that takes pictures of fruits and labels them accordingly.

