



 All living beings, be they flora or fauna, have a unique way of communicating and expressing their emotions using various sounds and signals. We humans are blessed with the capability to observe, learn, and speak many languages. We also possess an innate curiosity to know more about our ecosystem and the world around us. It is our wish to understand nature’s feelings. At the same time, we also want to share our feelings.
All living beings, be they flora or fauna, have a unique way of communicating and expressing their emotions using various sounds and signals. We humans are blessed with the capability to observe, learn, and speak many languages. We also possess an innate curiosity to know more about our ecosystem and the world around us. It is our wish to understand nature’s feelings. At the same time, we also want to share our feelings.
So, by employing these open source datasets you can develop and train a machine language (ML) model that understands the emotions in different animal sounds and classifies them accordingly. You will also be able to deploy the ML model for translating human language into nature’s language and back, enabling efficient communication.
Doesn’t it sound awesome? So, without wasting any time, let us start our beautiful journey.

Preparing datasets
The ML needs to be fed with correct data regarding sounds and emotions. You can download various open source datasets of different birds and animals available online such as sounds made by an elephant for communicating motion, love, care, anger, etc.
After downloading such animal sounds, compile them into datasets to train the ML model. You can use tools such as Tensorflow, Edge Impulse, SensiML, Teachable Machine, and many others available for this purpose. Here, I am using Edge Impulse.
Open the Raspberry Pi terminal and install Edge Impulse dependencies. Then using the following commands, create a new project named Fauna Translator:
curl -sL https://deb.nodesource.com/
setup_12.x | sudo bash –
sudo apt install -y gcc g++ make build-
essential nodejs sox gstreamer1.0-tools
gstreamer1.0-plugins-good gstreamer1.0-
plugins-base gstreamer1.0-plugins-
base-apps
npm config set user root && sudo npm install
edge-impulse-linux -g –unsafe-perm
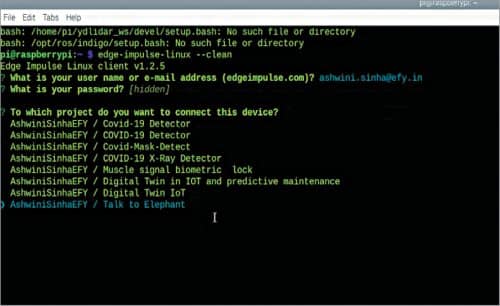
After this, connect the Raspberry Pi project with Edge Impulse using Edge-impulse-linux
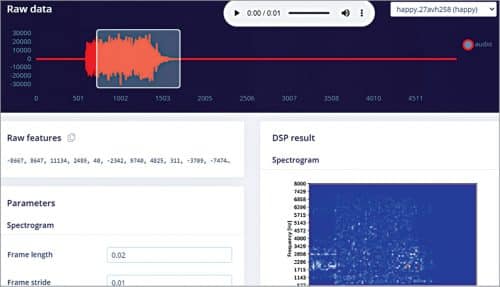
Next, open the terminal and select the project name, after which you are given a URL for feeding the datasets. In that URL, enter the captured sounds of animals and appropriately label them based on different emotions (angry, glad, hungry) or expressions (“Let’s go”, “I love you”).
Note
Before proceeding with sound data capture, put the AIY Voice bonnet onto the Raspberry Pi as shown in Fig. 1.

ML model
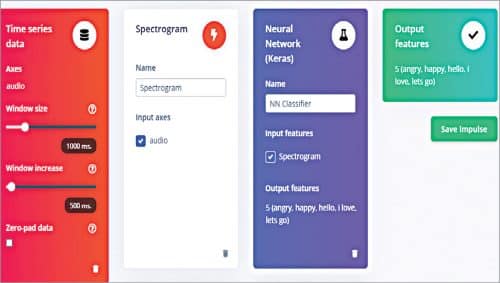
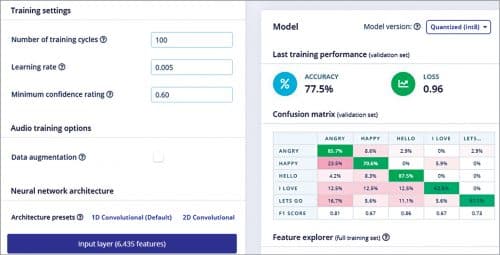
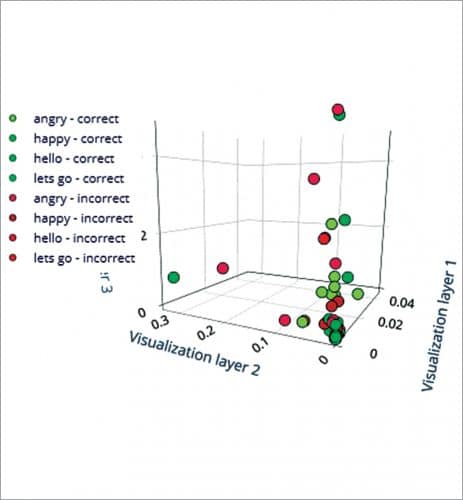
Select the learning and processing blocks for training the ML model. Here we use Spectrogram for the processing block and Keras for the learning block. Using these, extract different audio parameters for training the ML model to learn from datasets. Then test the model and keep refining it until you are satisfied with its accuracy.
To deploy the ML model, go to the deploy option and select Linux board. Install it and clone the SDK of edge impulse.
sudo apt-get install libatlas-base-dev
libportaudio0 libportaudio2 libportaudi
ocpp0 portaudio19-dev
pip3 install edge_impulse_linux -i https://
pypi.python.org/simple
pip3 install edge_impulse_linux
git clone https://github.com/edgeimpulse/
linux-sdk-python
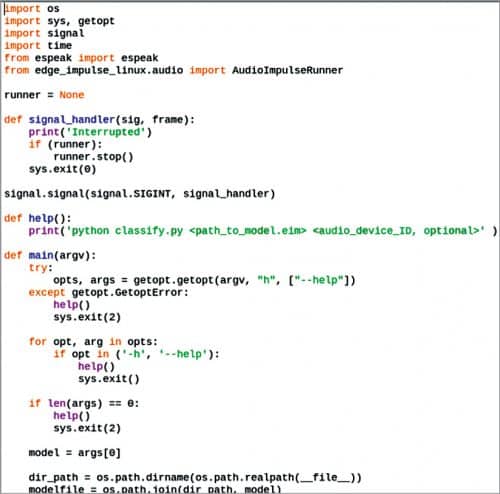
Coding
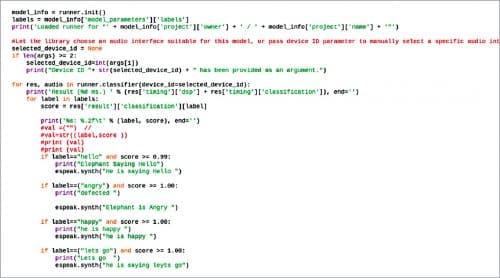
Create a .py file called animal_translate and import espeak in the Python code, which translates the animal sounds so that humans can understand them. Create an if condition for checking the accuracy of the emotion present in the output of the ML model. If the output accuracy of 98% or more for a particular label is detected, the output matches the label description. For example, if an animal’s sound for the label “hello” meets the said percentage, the animal is indeed saying “hello.”
 Testing
Testing
Download the .iem ML model file, open the terminal, and run animal_translate.py followed by the path location of the ML model. Select an animal, say elephant. So, whenever the elephant makes any sound, the ML model will capture that in real time and translate what the elephant is saying to you.

Congratulations! You have created perhaps the world’s first bird and animal language translator. Now you can understand nature’s language and even interact with it.
Download source code
Ashwini Kumar Sinha is an electronics hobbyist and tech journalist at EFYi
This article was first published online, you can read it here
