




Managing risks systematically and pragmatically is the key to handle artificial intelligence (AI) risks. The problem with AI risks is that these are highly scalable and can quickly grow out of control due to the power of automation and the sheer capacity of AI to execute tasks.
Risk mitigation can become a daunting task if there is no quantifiable measure attached to it. Following the maxim—if you can measure it, you can improve it—a systematic and measurable approach can come in handy.

The method explained in this article can help in establishing quantitative measures. Once you establish those measures, it can become easier to assess the risk and progress of mitigation activities.

The core principles
In the case of artificial intelligence (AI) risks, three core principles serve as a foundation. Generally speaking, these principles are essential for the effective management of risks of all kinds.
Identify risks
While using a systematic approach, one must determine the most severe risks. Without identification there cannot be any control or management. A good cross-section of the team is necessary to work on the risk identification process.
Be comprehensive
AI systems are not one-point solutions. These often involve several other systems, and the final system is pretty much a system of systems. This means that, to be effective, merely covering AI solution is not going to be helpful. You will have to be comprehensive in the risk identification process. Without being comprehensive, risks from other parts of the system can fall through the cracks and wipe out all the efforts.
Be specific
It is not difficult to design and implement AI solutions in a responsible manner. However, to do that, it is a prerequisite to understanding risks better and specifically to your application. Broad-based risk identification and management approach are not helpful. Moreover, establishing a control system across the value chain is also quite important.
Pre-mortem analysis
The term project pre-mortem first appeared in the HBR article written by Gary Klein in September 2007. As Gary writes, “A pre-mortem is the hypothetical opposite of a post-mortem.”
It is a project management strategy in which a project team imagines a project failure and works backward to determine what potentially could lead to that failure. This working is then used to handle risks upfront.
However, in the risk management context, we are going to use this (pre-mortem) term interchangeably to represent a more sophisticated and engineering-oriented methodology known as Failure Mode and Effects Analysis (FMEA).
Key elements of the pre-mortem analysis
Pre-mortem analysis or FMEA is typically done by a cross-functional team of subject matter experts (SMEs). A better format to conduct this exercise is in the form of a workshop.
During the workshop, the team thoroughly analyses the design and the processes are implemented or changed. The primary objective is to find weaknesses and risks associated with every aspect of the product, process, or both. Once you identify these risks, take actions to control and mitigate them, and verify that everything is in control.
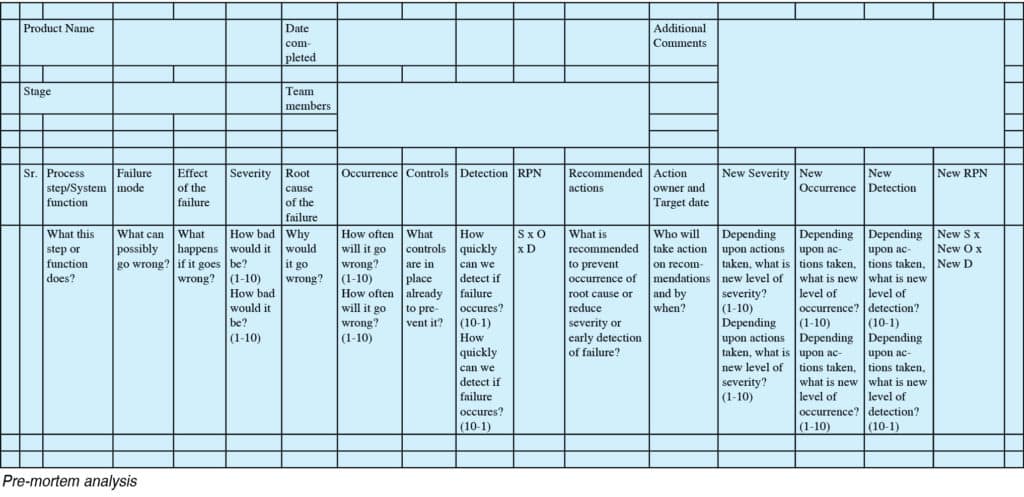
Pre-mortem analysis record has sixteen columns, as explained below:
Process step or system function. This column briefly outlines the function, step, or an item you are analysing. In a multi-step process or multi-function system, there would be several rows, each outlining those steps.
Failure mode
For each step listed in column #1, you can identify one or more failure modes. It is an answer to the question: In what ways the process or solution may fail? Or what can go wrong?
Failure effects
In case of a failure, as identified in column #2, what are its effects? How can the failure affect key process measures, product specifications, customer requirements, or customer experiences?
Severity
This column lists the severity rating of each of the failures listed in column #2. Use the failure effects listed in column #3 to determine the rating. The typical scale of severity is from zero to ten; zero being the least severe, while ten is the most severe consequence(s).
Root cause
For each failure listed in column #2, root cause analysis is done to find an answer to the question—What will cause this step of function to go wrong?
Occurrence
This column is another rating based on the frequency of failure. How frequently are these failures, as listed in column #2, likely to occur? Occurrence is ranked on a scale of one to ten, where one is a low occurrence, and ten is a high or frequent occurrence.
Controls
An answer to the question—What controls are in place currently to prevent potential failure as per column #2? What controls are in place to detect the occurrence of a fault, if any?
Detection
This is another rating column where ease of detection of each failure is assessed. Typical questions to ask are: How easy is it to detect each of the potential failures? What is the likelihood that you can discover these potential failures promptly or before they reach the customers? Detection is ranked on a scale of ten to one (please note reversal of the scale). Here rating of one means easily and quickly detectable failure, whereas ten means unlikely and very late detection of failure. Late detection often means a more problematic situation, and therefore the rating for late detection is higher.
RPN (Risk Priority Number)
The risk priority is determined by multiplying all the three ratings from column #4, 6, and 8. So, RPN = Severity x occurrence x detection. Thus, a high RPN would indicate a high-risk process step or solution function (as in column #1). Accordingly, steps or functions with higher RPN warrant immediate attention for fixing.
Recommended actions
In this column, SMEs would recommend one or more actions to handle the risks identified. These actions may be directed towards reducing the severity, chances of failure occurrence, improving the detection level, or maybe all of the above.
Action owner and target date
This column is essential from the project management point of view as well as for tracking. Each recommended action can be assigned to a specific owner and carried out before the target date to contain the risks.
Actions completed
This column lists all the actions taken, recommended, or otherwise to lower the risk level (RPN) to an acceptable level or lower.
New severity
Once the actions listed in column #12 are complete, the same exercise must be repeated to arrive at a new level of severity.
New occurrence
The occurrence must have changed depending on actions completed, so this column has a new occurrence rating.
New detection
Due to risk mitigation actions, detection must have changed, too. Register it in this column.
New RPN
Due to change in severity, occurrence, and detection ratings, risk level would have changed. A new RPN is calculated in the same way (severity x occurrence x detection) and recorded in this column.
A usable and handy template for pre-mortem analysis is available for free download.
More about ratings
Several risk analysis methodologies often recommend only two rating evaluations, i.e., severity and occurrence. However, in the case of pre-mortem analysis, we are using the third rating—Detection.
Early detection of the problem can often enable you to contain the risks before becoming significant and out of control. This way, you can either fix the system immediately or may invoke systemwide control measures to remain more alert. Either way, being able to detect failures quickly and efficiently is an advantage in complex systems like AI.
In case of severity and occurrence ratings, the scale of one to ten does not change—no matter what type of solution or industry you are doing it for.
In implementing pre-mortem analysis, you must take a pragmatic approach and choose the scale as appropriate. Just make sure that you are consistent in your definitions throughout the pre-mortem exercise.
While conducting a pre-mortem workshop, participants must set and agree on rankings criteria upfront and then on the severity, occurrence, and detection level for each of the failure modes.
How to use the output of pre-mortem
The output of the pre-mortem analysis is only useful if you use it.
Each process step or system function would have one or more RPN values associated with it. The higher the RPN, the riskier the step is.
Before the pre-mortem exercise, the team must decide a threshold RPN value. For all the steps where RPN is above the threshold, risk mitigation and control plan become mandatory. For the ones below, risks may be addressed later as their priority would be lower.
Ideally, you should be addressing all the practical steps wherever RPN is non-zero. However, it is not always possible due to resource limitations.
One of the ways you can reduce RPN is by reducing the severity of the failure mode. Typically, reducing severity often needs functional changes in process steps or the solution itself. Additionally, the occurrence can be controlled by the addition of specific control measures such as a human in the loop or maker-checker mechanisms.
However, if it is not possible to reduce the severity or occurrence, you can contain the failures by implementing control systems. Control systems can help in the detection of causes of unwanted events.
Having risks quantified and visible enable you to have plans in place to act quickly and appropriately in case of failures and thus reduce the exposure to more failures or adverse consequences.
A common problem I have seen in this exercise is difficulty or failure to get to the root-cause of anticipated failure, and this is where SMEs should lean in. If you do not identify root-causes correctly, or do it poorly, your follow-up actions would not yield proper results.
Another problem I have seen is the lack of follow-up to ensure that recommended actions are executed, and the resulting RPN is lowered to an acceptable level. Doing effective follow-through is a project management function. It needs diligent execution to ensure that pre-mortem analysis reaches its logical conclusion.
Pre-mortem analysis workshops can be time-consuming at times. Due to high time demand, it may become challenging to get sufficient participation of SMEs. The key is to get the people who are knowledgeable and experienced about potential failures and their resolutions showing up at these workshops. SME attendance often needs management support, and facilitators need to ensure that this support is garnered.
Sector-specific considerations
In the pre-mortem analysis, severity-occurrence-detection (SOD) ratings range between one and ten. However, the weights assigned to each of the rating values are subjective. It is possible that in the same industry, two different companies could come up with slightly different ratings for the same failure mode.
If you want to avoid subjectivity and confusion, standardisation of the rating scale will be necessary. However, this would be only necessary when you are benchmarking two or more products from different vendors in the same industry. If this has to be used only for internal purposes, subjectivity will not matter much since relative weights will be still preserved within the risks and action items.
Nonetheless, when considering control or action plans for identified risks, sector-specific approaches could be (and should be) different.
Any failure risk can be controlled by reducing severity (S), lowering the chances of occurrence (O), or improving detection levels (D). If this were to be done in the banking sector while enhancing S and O ratings, D ratings might need additional focus for improvement.
Given the volume of transactions that the financial sector carries out every day, the severity of failure could be high due to widespread impact. But if the severity cannot be controlled beyond a point, detecting it early to fix would be highly necessary.
For the healthcare sector, severity itself should be lower as the detection may likely result in fixing a problem but would not necessarily reverse the impact. For example, if AI prediction or solution results in an incorrect prognosis, early detection of this problem may result in stopping the activity per se. However, it will not be able to revert the issues caused by having this failure in the first place.
Similarly, in transportation scenario, especially for autonomous cars, detecting that a car’s mechanism has failed as an after the fact is less useful since the accident would already have happened. Reducing severity and occurrence in those cases is a more acceptable course of action.
Severity and occurrence improvement are prevention-focused, whereas detection improvement is fixing (cure) focused. If your industry believes that prevention is better than cure, then work on reducing the severity and lowering the occurrence of failures. If your industry is comfortable with fixes after the fact, detection must be improved.
However, in my view, it is better to address all three factors and ensure that robust risk management is in place.
Conclusion
Pearl Zhu, in her book, Digitizing Boardroom, says, “Sense and deal with problems in their smallest state, before they grow bigger and become fatal.”
Managing risks systematically and pragmatically is the key to handle AI risks. The problem with AI risks is that these are highly scalable and can quickly grow out of control due to the power of automation and the sheer capacity of AI to execute tasks.
Moreover, subjectivity in risk management is a myth. If you cannot quantify the risk, you cannot measure it. And if you cannot measure it, you cannot improve or control it. The systematic approach outlined here will help you quantify your risks, understand them better while maintaining the context of your use case.
You can develop and implement AI solutions responsibly. If you understand risks, understand them better and specific to your use case!
Anand Tamboli is a serial entrepreneur, speaker, award-winning published author, and emerging technology thought leader