




Language models are revolutionizing robotic precision, merging linguistic intelligence with task execution, and reshaping the future of robotics.
Large language models (LLMs) have shown notable advancements in context-driven learning, from logic to coding. However, due to the hardware-specific nature of basic robot actions and their limited presence in LLM training datasets, most attempts to integrate LLMs into robotics have used them mainly as strategic planners or depended on manually designed controls to interact with the robot.

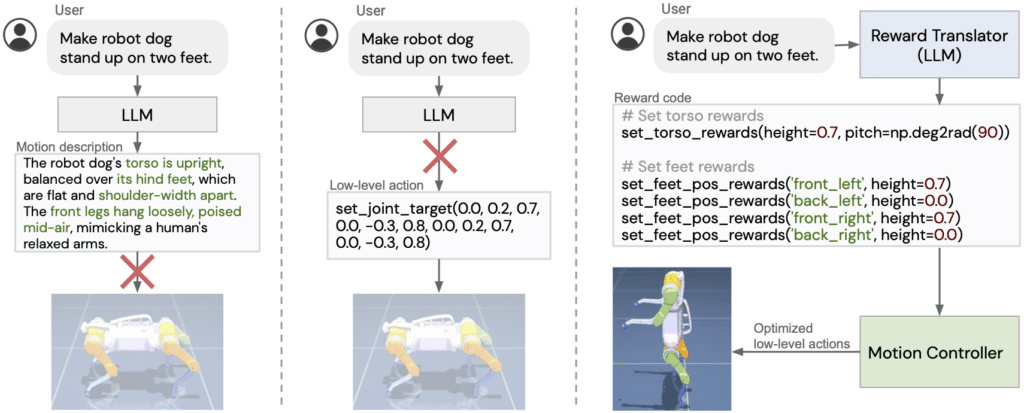
Researchers at Google DeepMind aim to develop an interactive framework that harnesses LLMs to master foundational robotic tasks. It has two main parts – a Reward Translator based on established LLMs that communicates with users and adjusts reward parameters and a Motion Controller using MuJoCo Model Predictive Control (MPC) that uses this reward to select the optimal action sequence.
Reward Translator
Using LLMs, the researchers have designed the Reward Translator to transform user interactions into corresponding robot motion reward functions. Recognizing the domain-specific nature of reward tuning, they expect generic-trained LLMs to refrain from directly generating hardware-specific rewards. Instead, they utilize their in-context learning. The team have broken the language-to-reward challenge into motion description, where a prompt refines user input into a set robot action template, and reward coding, where another prompt translates this description into reward code.
Motion Controller
The Motion Controller translates rewards from the Reward Translator into optimized robotic actions. The researchers have employed an open-source tool built on the MuJoCo simulator called MJPC. MJPC designs a series of refined actions during each control interval, which are then transmitted to the robot. The robot then executes the action relevant to its current timeframe, moves to the succeeding step, and forwards the refreshed robot conditions to the MJPC for the commencement of the following planning stage. The regular replanning inherent in MPC offers resilience against system uncertainties and crucially facilitates dynamic motion design and adjustments.
Results
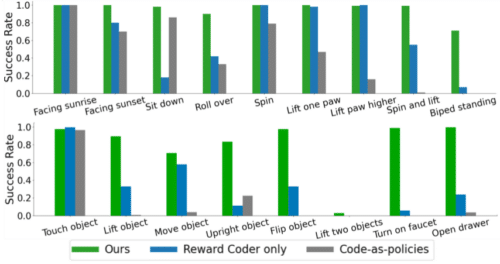
The team has used two simulated robotic systems, a quadruped robot and a dexterous robot manipulator, for evaluation. They create a varied assortment of tasks for each robot to showcase the effectiveness of our suggested system. The researchers compared their method to two baselines. First is the Reward Coder, where an LLM directly translates user commands to reward code, bypassing the Motion Descriptor. Second, the Code-as-Policies approach, where the LLM uses predefined robot skills instead of reward functions. These skills are based on common robot commands. The results have shown that it excels in 11 of 17 task categories and matches performance in the rest, emphasizing its effectiveness.
Validation on real hardware
The researchers applied their method to a mobile manipulator using the F-VLM detector to identify objects in images. Extracting points from the point cloud, they reject background outliers and use a minimal rectangle from a bird’s eye view to measure the z-axis. Demonstrating sim-to-real transfer for object pushing and grasping, the system produces the correct reward code, and Mujoco MPC creates the desired motions.