



Get to know the Generative Pre-Trained Transformer (GPT) better, before you consider putting it to any serious use
ChatGPT is writing essays, answering questions on the Bhagavad Gita, suggesting menu options for lunch, coding, and debugging code, writing new episodes of Star Wars, proposing itineraries for vacation travel, and even completing assignments for students. It garnered a million users faster than any well-known app in recent times. Perhaps because it is filling in for the much-missing human interaction in people’s lives today. Almost everyone is talking about it and enjoying the conversation too—till it gets technical.
Artificial intelligence (AI) of this scale is not easy to understand—or explain. And the profuse use of jargon makes things worse. On the other hand, it is mandatory to know more about it, especially if we plan to make any professional use of the tool. So, in this article, we attempt to cut through the jargon with the help of some experts on the subject. This will help us understand the technology behind this chatbot, how it is different from others, what it is capable or incapable of, how to use it, whether there are other such worthy AI models, what the future hold for it, and so on.
For some time, let us cut the chat and focus on the GPT!
AI is Everywhere… How is ChatGPT Different?
AI is all around us. From Netflix recommendations and browser ads to a game of chess, and those decision-influencing insights that a banking platform’s dashboard provides, it is all artificial intelligence. By now, we are all used to specific intelligence—being smart at one or few things (which applies to most of us also!). Yet, the kind of general intelligence and conversational skills displayed by OpenAI’s ChatGPT makes one’s nerves tingle—in anticipation, and in fear.
“There are two main differences between ChatGPT and traditional conversational AI models: the technology and user experience,” remarks Anurag Sahay, CTO, and Managing Director – AI and Data Science, Nagarro.
In terms of technology, ChatGPT distinguishes itself by being based on the most advanced generative pre-trained transformer (GPT) language model available today, which uses a transformer architecture with a large number of parameters that allows it to learn and generate human-like text. This model exhibits greater capability in comprehending context, drawing generalizations from examples, and furnishing responses that are more precise and pertinent when contrasted with conventional conversational AI models.
The free version of ChatGPT is currently based on GPT-3.5, while the paid ChatGPT Plus is based on the GPT-4 platform, launched in March 2023. GPT-4 is multi-modal. It can handle text and image inputs. You can scan graphs, books of accounts, or question papers and get answers from them.
OpenAI says GPT-4 can solve difficult problems with greater accuracy thanks to its broader general knowledge and problem-solving abilities. It is apparently more intelligent because it has scored higher in benchmark exams like the graduate record examinations (GRE) and the scholastic assessment test (SAT).
With respect to user experience, ChatGPT conversations are more engaging and interactive compared to traditional conversational AI models. Sahay feels that “This is because ChatGPT has a clearer understanding of context, which allows it to maintain a more coherent conversation and respond specifically to user queries. As a result, users feel like they are talking to someone who is intelligent, knowledgeable, and empathetic, which makes the interaction more natural and human-like. On the other hand, when users talk to a bot built with traditional conversational AI models, they may not feel that the agent on the other end truly understands them or is empathetic. Overall, the combination of ChatGPT’s advanced technology and more natural user experience sets it apart from traditional conversational AI models.”
Sanjeev Azad, Vice President – Technology, GlobalLogic, also feels that one of the key differentiators of ChatGPT is its adaptability—“The way it quickly adapts to the user’s communication style based on the questions asked, and personalizes responses as per the user’s need.”
He further explains that the power and effectiveness of large language models can be evaluated in various ways, but the two most considered factors are the number of parameters and the extent of language coverage. GPT-3 has more than 175 billion parameters. Although the number of parameters of the multi-modal GPT-4 is not officially available as of the date this story is filed, it is rumored to be more than a trillion.
ChatGPT can converse in any language as long as it has been trained on enough data in that language. According to a report by seo.ai, ChatGPT knew 95 natural languages, as of February 2023. It has also been trained in several programming languages, including Python, Java, C++, JavaScript, and Ruby.
OpenAI’s GPT is not without contenders in this respect. WuDao 2.0, a multi-modal AI developed by the Beijing Academy of Artificial Intelligence, has around 1.75 trillion parameters and can handle conversations in English and Chinese. The Megatron-Turing Natural Language Generation Model, a collaboration between Microsoft and Nvidia, uses novel parallelism to achieve 530 billion parameters.
BigScience’s open-access AI, Bloom, can supposedly handle 46 natural languages and 13 programming languages, with its 176 billion parameters. Google’s Language Model for Dialogue Applications (LaMDA), which powers Bard, has 137 billion parameters.
“Yes, there are other powerful transformers and large language models besides GPT-3, but GPT-3 has gained the maximum popularity to date,” remarks Azad.
How ChatGPT Works?
Azad spends some time explaining the working of ChatGPT to us. “ChatGPT uses a large neural network to generate responses to user inputs. The neural network is trained on massive amounts of text data and uses this knowledge to generate responses similar in style and content to human-generated text.”
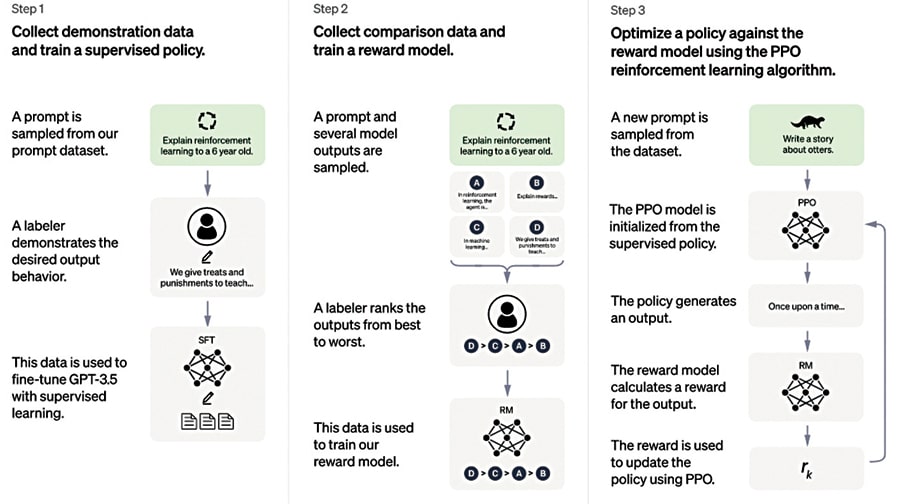
He explains the working of ChatGPT in five steps:
Step 1 – Pre-processing: This is the first step to ensure we have the relevant data to feed into the neural network, as neural networks require a lot of computing power to process the information. This includes steps such as tokenization, where the input is split into individual words, and encoding, where each word is converted into a numerical representation.
Step 2 – Neural network: At its core, a neural network uses a ‘transformer architecture’ technique to process the input and generate a response. This architecture allows ChatGPT to model complex relationships between words and generate grammatically correct and semantically meaningful responses.
Step 3 – Language modeling: The neural network uses a language model to predict the most likely words to follow the user’s input. The language model is trained on vast text data and uses this knowledge to make predictions.
| Demystification Zone |
|
Let us first cut through some of the jargon you are likely to encounter in this and other articles on ChatGPT… Foundation models: We could say that foundation models are, well, foundational to today’s AI revolution! Foundation models induce an element of reusability in AI systems, rather than having to create and train task-specific AI models for every single requirement that arises. Foundation models are trained on large, unlabelled datasets and then fine-tuned or trained for specific applications. “Typically, foundation models are trained using some self-supervised tasks, such as learning, to predict the next word in a sequence of words. Using a foundation model, very little supervised data is required to develop a model for any specific task. A very popular deep learning architecture that is used nowadays for learning language-based foundation models is the transformer architecture,” says Sachindra Joshi of IBM Research India. Transformer models: Transformer models track relationships in sequential data and use that to understand context and meaning. Transformers use a technique called self-attention to focus on relevant parts of an input and make more accurate predictions. “Transformer models are a specific kind of deep learning architecture, which learn the representation of a token (word) based on all the other token representations in a text. This model is very effective in learning good token representations, and the computations required to learn these representations can be easily parallelized using GPUs. This makes it possible to use an enormous amount of textual data to learn very effective token representations,” explains Joshi. (The paid subscriptions to ChatGPT and other AI tools measure your usage based on tokens—now, we have demystified that term as well! According to OpenAI, 1000 tokens would roughly measure up to 750 words.) Large language models: Large language models (LLMs) are considered to be one of the most successful applications of the transformer model. LLMs are pre-trained using massive volumes of unlabelled data. The LLM learns high-level features at this stage. It can then be fine-tuned for specific tasks. If you take the example of ChatGPT, it has been pre-trained using troves of textual data from the internet, from which it has learned to understand the context and meaning well enough to hold mostly meaningful conversations with users. As a next step, users can utilize the ChatGPT API to make their own apps, fine-tuned and trained for specific purposes, say, to answer questions on Indian history, the Bhagavad Gita, or customer queries about a company’s products. LLMs can be used for more than natural language processing. They can also be used to study and predict patterns in weather, protein structures, financial data, cyber frauds, and more! Generative AI: Generative AI is a term that is used to refer to any model that can generate some content—could be text, images, or audio—in response to a prompt. ChatGPT and Dall-E are popular examples in today’s context. Multimodal AI: It can understand and respond in multiple modes, such as text, images, and audio. You could, for example, input an image or a graph as part of your prompt. The latest version from OpenAI, GPT-4, released in March 2023, is multimodal. |
Step 4 – Beam search: ChatGPT uses a technique called ‘beam search’ to ensure that the generated response is grammatically correct and semantically meaningful. This involves generating multiple possible responses and selecting the one that is most likely to be correct based on a set of criteria, such as the likelihood of each word in the response.
Step 5 – Post-processing: Once the neural network has generated a response, it is post-processed to ensure that it is in a format that is easy for the user to read and understand. This includes steps such as converting numerical representations back into words and ensuring that the response is grammatically correct.
“These steps necessitate a significant amount of computing power, and ChatGPT relies on high-performance hardware to ensure that it can generate responses quickly and accurately. It generally requires powerful graphics processing units (GPUs) or tensor processing units (TPUs) to handle the massive amounts of data involved in natural language processing,” he explains.
Platforms like Microsoft Azure and IBM Cloud come to the rescue, providing a seamless fabric of compute power required to train AI models. According to reports, ChatGPT initially used a Microsoft Azure supercomputing infrastructure, powered by Nvidia GPUs, which Microsoft built specifically for OpenAI. This year, after Microsoft announced its multi-year investment in OpenAI, it also phenomenally upgraded OpenAI’s infrastructure.
| Is ChatGPT Open Source? |
|
Despite the company being called OpenAI, the code of ChatGPT is not open-sourced. Since the company was not available for comment, we asked ChatGPT itself about it, and here is what it had to say: “As an AI language model, my code is not open-sourced. However, the underlying technology that powers me is based on research and development by OpenAI, and some of the tools and libraries used to create me are open source. OpenAI has also released several pre-trained models for use in natural language processing tasks, which are available for free download and use. If you’re interested in exploring these resources, you can find more information on the OpenAI website.” This is something that has miffed many in the open-source world because ChatGPT uses quite a lot of open-source components and open knowledge as well. (Practically most of its training has happened on information garnered from the Web, contributed by people from around the world.) Perhaps it is not giving back as much as it takes. |
Sachindra Joshi, IBM Distinguished Engineer, Conversational Platforms, IBM Research India, remarks that “Building and deploying foundation models requires proper infrastructure. Training models like ChatGPT requires thousands of GPUs, making it extremely difficult for many entities to train these kinds of models from scratch. Deploying these models for inference is also very resource consuming and a lot of research is happening around better learning models with fewer parameters, and making inference costs cheaper.”
With Great Power Comes Great Responsibility
All that impressive technology working in the background gives you not just a lovable chatbot that you can chat and while away your time with, but also a very capable API that can be used to enhance applications and business platforms.
ChatGPT can converse on varied subjects, draft emails, make lists, translate text into different languages, summarise long texts, assist in various domains like education, healthcare, finance, and customer service, and do much, much more. It can adapt to different communication channels and be integrated with external data sources and application programming interfaces (APIs) to provide more customized and comprehensive responses.
Hand-in-hand with all this power comes a lot of risk as well. From privacy and plagiarism to cybersecurity issues, and the very serious possibility of it dumbing down the human brain, there are several issues that we must be aware of, so we can make responsible use of generative AI.
Indeed, ChatGPT has taken trendwatchers by surprise, by racing to the peak of the hype cycle within a phenomenally short span of time. Unlike the metaverse, which people are still struggling to understand, let alone adopt, generative AI (especially ChatGPT) has already proved its worth to people and seems to be here to stay.
“ChatGPT has revolutionized the accessibility of AI to the masses, providing people with the opportunity to interact with it in ways that were once exclusive. The pace at which enterprises are investing in AI is remarkable, having surged by 2.5 times over the last five years. Yet, the number of AI products available today is several multiples higher than it was in 2017. The impact of this disruption is truly remarkable,” says Sahay.
He explains that, in the near future, these generative AI models will become better, less expensive, and more accurate. Because these models are becoming multimodal, a single model will soon be able to synthesize information from all four modalities—text, image, video, as well as speech.
Sahay signs off by saying, “This is a critical future element that everyone is anticipating, and will be more closely monitored and moderated for ethical reasons. There is no doubt that everyone is on board to ensure that both privacy and accountability are addressed and that more regulation and governance in this area are clearly needed.”
Janani G. Vikram is a freelance writer based in Chennai, who loves to write on emerging technologies and Indian culture. She believes in relishing every moment of life, as happy memories are the best savings for the future