




Delve into Coverage Path Planning (CPP) with reinforcement learning, extending mission durations and enhancing safety and how it empowers drones to navigate diverse terrains, optimise trajectories, and ensure mission success.

Unmanned aerial vehicles (UAVs), more commonly called drones, have already demonstrated immense value in addressing real-world challenges. They have proven instrumental in aiding humans in deliveries, environmental monitoring, filmmaking, and search and rescue missions. While there have been significant advancements in the performance of UAVs over the past decade, a notable limitation persists: many drones have relatively limited battery capacity, which can lead to premature power depletion and mission interruption.
Recent research endeavours in robotics have focused on enhancing the battery life of these systems while simultaneously developing advanced computational techniques to optimise mission execution and route planning. Researchers from the Technical University of Munich (TUM) and the University of California Berkeley (UC Berkeley) have been diligently working to develop improved solutions for addressing a fundamental research challenge known as coverage path planning (CPP).
Reinforcement Learning for UAV
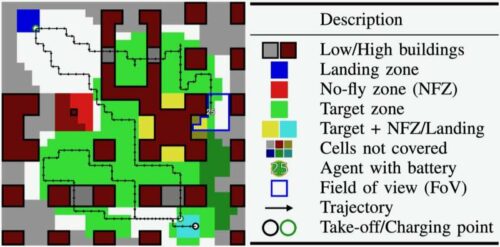
Their approach involves the application of reinforcement learning to optimise the flight paths of unmanned aerial vehicles (UAVs) across a mission, encompassing essential stops at charging stations when their battery levels run low. Over several years of dedicated research, it has become evident that CPP plays a pivotal role in enabling the deployment of UAVs across diverse application domains, including but not limited to digital agriculture, search and rescue operations, surveillance, and numerous others. Solving this complex problem necessitates the consideration of numerous factors, such as collision avoidance, camera field of view, and battery longevity.
Researchers applied reinforcement learning to enable UAVs to complete missions or traverse extensive areas on a single battery charge, avoiding interruptions for recharging. The agent learned safety constraints like collision avoidance and battery limits, but not always perfectly. Extending the CPP problem involved allowing agents to recharge for greater coverage. Ensuring safety was vital in real-world scenarios. The advantage of reinforcement learning lies in its generalisation ability, allowing models to handle new, unencountered problems and scenarios after training.
Deep Learning Model and Map-Based Problem
The extent of generalisation largely relies on how the problem is framed for the model. To facilitate this, the deep learning model should be capable of structuring the given situation, typically in a map. This model surveys and interprets the environment in which a UAV operates, represented as a map, and focuses on the UAV’s current position. Subsequently, the model condenses the entire “centred map” into a lower-resolution global map while generating a full-resolution local map detailing the robot’s immediate surroundings. These two maps are then meticulously analysed to optimise UAV trajectories and determine their forthcoming actions.
The agent extracts vital information for addressing challenges in new scenarios through their map processing pipeline. They established a safety model for action guidance and used action masking to optimise choices. Their tool surpassed baseline planning in tests, showcasing strong generalisation, even with uncharted maps. This reinforcement learning approach guarantees UAV safety and improves mission efficiency, including route optimisation for points of interest, targets, and recharging stations during low battery life.
The team highlighted that the CPP problem with recharging presents substantial challenges due to its extended time horizon. The agent must make strategic, long-term decisions, such as prioritising current coverage versus coverage upon returning to recharge. They demonstrate that an agent equipped with map-based observations, safety model-guided action masking, and additional considerations like discount factor scheduling and position history can make robust long-horizon decisions.