



The human mind is arguably the most complex in this world. Utterly fascinating, it is an object of admiration to everyone. Some people take this admiration to a higher level and try to understand how the brain does what it does. Others go even further and attempt to replicate this marvel of a creation. While this is no mean task, science is a lot closer to creating artificial intelligence (AI) today than it was a few years ago.
This article takes you through a tool that provides an environment for R&D in AI domain. Be it to make a software application smarter or to create your own clone, this tool provides the very basic raw materials you need to start with, and may be carves out a path and guides you along. But, it is no cake-walk. The tool we are talking about is OpenCog.

Apt for research in AI
OpenCog is an open source software project, which aims to create an open source framework for artificial general intelligence. The developers state, “We are undertaking serious effort to build a thinking machine.” While this is stretching it too far for the present, the team behind OpenCog presently aims at nurturing the R&D environment and creating a code that can help make smarter systems, and working towards developing cognitive capability at the human level.
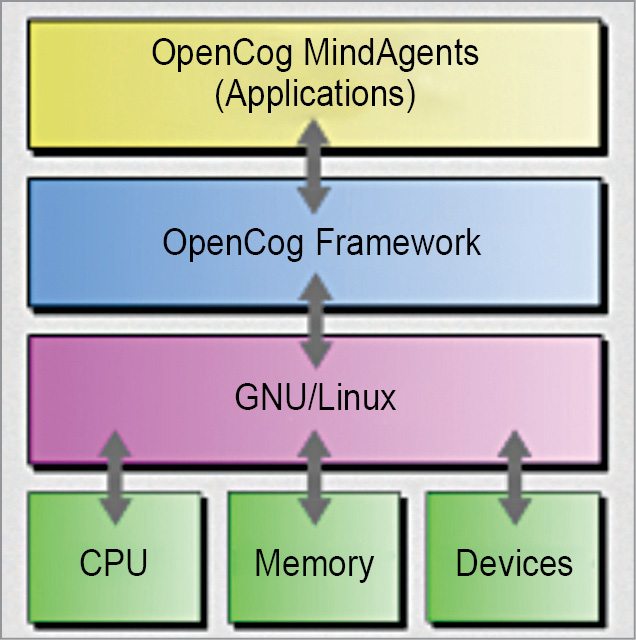
OpenCog has been developed by OpenCog Foundation under GNU Affero general-public licence and is supported by Artificial General Intelligence Research Institute (AGIRI), Google Summer of Code project and others. It is written using a combination of C++, Python and Scheme, and is built for Linux platform. The software is currently under an early stage of development, and is mostly useful for building applications that require significant AI capability. This is an interesting and powerful AI platform, but you will need to make significant customisations and integrations to get your projects up and running.
Keeping the first foot forward
Prime inspiration for the project is the artificial general intelligence theories by Dr Ben Goertze. The concept of probabilistic logic networks is made extensive use of, to robustly handle uncertainty and perform effective reasoning in real-world circumstances. The idea is a novel conceptual, mathematical and computational approach to uncertain inference.
Well, you have seen what to expect from this tool, but it is still not clear as to how you can go about working with it. Building a cognitive system is easier said than done, and certainly that much more complicated for someone just beginning to work with AI. Let us begin by trying to understand how OpenCog goes about creating AI.
The knowledge base.
The first step is to create a system that stands for the knowledge inside the memory of an intelligent system, called knowledge representation. While this details the basic nature and organisation of knowledge components, it could be highly complex and dynamic, or simple, static and easy to describe. The catch here is how explanatory you want the knowledge representation to be. Does it have to be a repeated looping of a basic element, specialising for different situations? Or, does it have to be based on a learning algorithm that develops knowledge representations as time progresses? In OpenCog, they call this knowledge representation AtomSpace.
AtomSpace, the very basic.
It is in AtomSpace that different components of the intelligent system you have in mind are held, and this is also the query/reasoning engine that fetches data, manipulates it and performs reasoning on it. Effectively, AtomSpace is a kind of graph database, where graphs are representations of data and procedures. What this means is that graphs can be data, executable programs or data structures. AtomSpace could also have hypergraphs. The vertices and edges of the graphs are atoms, which essentially capture the notion of an atomic formula in mathematical logic.

How to use these to develop your system
What you have to do is use atoms to form small portions of the mind, which when put together form the complete system. You cannot code line-by-line per se, as the system is built for use by automation and machine learning engines. Automated sub-systems manipulate, query and inference over data or programs, and work to manipulate networks of probabilistic data by means of rules, inferences and reasoning systems. These are similar to an extension of probabilistic logic networks to a generalised system where data is automatically managed.
Atomese, the programming language.
The above programming-like language is informally referred to as Atomese. Developers describe Atomese as a strange mash-up of SQL, prolog/datalog, lisp/scheme, haskell/caml and rule engines. Most engines provide basic atoms that represent relations like similarity, inheritance; logic like Boolean or, there-exists; for Bayesian and other probabilistic relations; intuitionist logic like absence and choice; thread execution; and expressions including variables, mapping or constraints. As a programming language, Atomese is probably inefficient, slow and not scalable, but powerful as an input to automation sub-systems.
Putting the better of the two together. AtomSpace and Atomese together let you integrate your needs for dependent systems like machine learning, natural language processing, motion control and animation, planning and constraint solving, pattern and data mining, question answering and common-sense systems, and emotional and behavioural psychological systems. You can start off with the examples section in OpenCog to get a hand over Python and Scheme bindings, pattern matcher, rule engine and other different atom types, and learn how to use these for solving various tasks.
AtomSpace, a boon in disguise
Simplifying things a little further, you have to work with these AtomSpaces instead of individual atoms, as there are advantages of de-duplication, fast searches by atom type or name, automated attention-allocation management and automated atom fetch and save to a persistent database, and automatic sharing of this database by multiple machines in a cluster.
You can put together multiple AtomSpaces as different threads on the same machine, to perform complex tasks. Atoms can be uniquely identified by handles, and AtomSpace has signals that are delivered when an atom is added or removed, which can then be configured to trigger other actions. A persistence backend allows multiple AtomSpaces on multiple networked servers to store atoms on a disk or different machines, and communicate and share atoms.

Managing generated data
While dealing with any kind of system, memory management becomes very important. How do you handle the vast expanse of data that is generated? What do you do when there is a lot of old data already? How do you prioritise? OpenCog terms this entire process as attention allocation. Pieces of knowledge are weighed relative to one another, taking into account how important a certain piece of data has been in the past and how important it is currently. This calculated analysis then guides the processes of:
Storing knowledge.
What to store in memory, what to store locally on a disk and what can be off-loaded to other machines
Deleting information.
To guide the process of forgetting data that is no longer needed or what has been integrated into the system in other ways
Reasoning.
To prioritise which threads of data should be taken into account while making any kind of decision, to analyse the combinatorial explosion of potential inference paths and cut off the ones with very low importance.
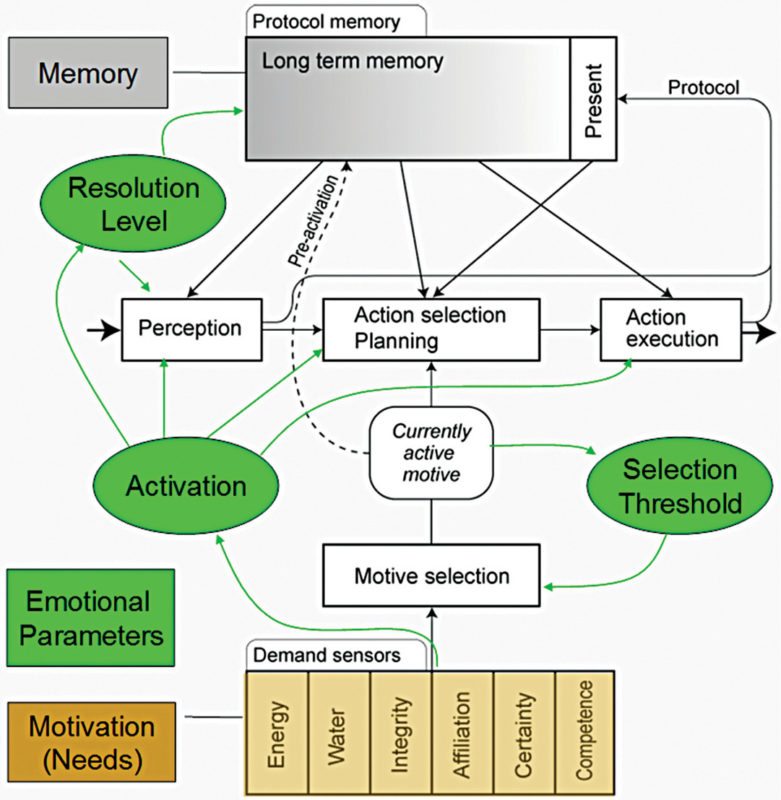
OpenCog uses available hardware resources to run software, taking a cue from neuroscience, cognitive psychology and computer science. One principle that OpenCog works on is that, intelligence is not owned by a single algorithm. Instead, it is a culmination of a large number of algorithms that work in cognitive synergy. The intelligent agent’s motivations, drives, emotions and decisions are driven, higher-level features of cognition emerge based on the way the system is setup and its interaction with the environment.
Download the latest version of the software: click here