



Part 1 of this article dealt with an introduction to convolutional neural networks, training and simulation, image identification and depth estimation. This part covers the future of the networks including decision making and technology enablers.
The trainable, multi-layered structure of convolutional neural networks (CNNs) sets them apart from other neural networks. Their layers can be customised by adjusting their parameters to best fit their intended function. Neurons are constantly improving the accuracy of their outputs by learning from each piece of input data. This is particularly useful for applications in autonomous vehicles.

Capabilities of CNNs to distinguish both the presence and depth of obstacles make them promising backbones for autonomous transportation. However, ethical decision making in the face of a collision still provides a considerable obstacle to the use of autonomous vehicles in everyday life as these are not yet proven to be safer than human drivers. On the other hand, these vehicles will promote sustainability by decreasing energy consumption and environmentally harmful emissions while reducing wear on vehicle parts. The more the research is done on CNNs in autonomous vehicles, the closer we will get to these vehicles as the main form of transportation.
Development of a sustainable driving environment
A mechanism for deciding the best route can be included in the neural network of each vehicle. This route optimisation and resulting decrease in traffic congestion are predicted to reduce fuel consumption by up to 4 percent, thus reducing the amount of ozone and environmentally harmful emissions.
Each vehicle will have a set of commands learnt for different driving situations. When efficiency and part preservation are the priority, commands will be executed to minimise wear on the vehicle and reduce energy consumption by 25 percent. For example, a human driver stuck in traffic might hit the accelerator and then the brake excessively to move every time the traffic inches forward. This causes excessive wear on the engine and brakes of the vehicle. However, an autonomous vehicle system would be optimised to either roll forward at a slow enough rate so that it does not collide with the vehicle ahead, or not move until there is enough free road available. This will decrease wear on the vehicle’s brakes and engine while optimising fuel efficiency. As a result, the lifespan of each vehicle will extend, thus decreasing demand for new vehicles and vehicle parts. Fewer vehicles manufacturing means conservation of resources such as fuels burnt in factories and metals used in production.

Decision making needs to improve a lot!
Decision-making process for autonomous vehicles is complex and can sometimes fail to prevent a crash in an unexpected or unpredictable situation. Autonomous vehicles still cannot consider numerous ethical factors including passenger safety, the safety of the people outside the vehicle and human intervention. The network simply considers the driving command based on the scene features.
Many nuances of these ethical factors are pushed aside in favour of assurances that the human in the driver’s seat will intervene and the car will not be required to take any action other than to alert the driver. However, in reality, it cannot be assumed that the drivers will have the time and focus to react, or that they will make a decision that is better than CNN’s. Even if an autonomous vehicle system could be programmed to determine which path the vehicle should take in any given scenario, extensive testing would be necessary to provide evidence that autonomous vehicles are, in fact, safer than human drivers.
A common misconception is that autonomous vehicles will provide a safer, crash-free future for transportation. While this is the main goal of autonomous transportation, statistics are yet to support this claim. Although computerised systems can compensate for human errors such as emotional distractions and insufficient reaction times, collisions cannot yet be completely avoided.
There are some factors that a computer cannot predict in a crash situation. In a potential crash situation, the CNN is responsible for making two decisions: whether a collision is going to occur on the vehicle’s current path, and if so, which new path to take. According to mileage data collected in 2009, a CNN controlled vehicle would have to drive 1,166,774km (725,000 miles) without human intervention to maintain a 99 percent confidence that it can drive more safely than a human driver. While there have been many advances in autonomous vehicle technology, more testing is needed before it will create a legitimately safer driving environment.
CNN technology enablers
OpenVX
The Khronos Group is working on an extension that will enable CNN topologies to be represented as OpenVX graphs mixed with traditional vision functions. OpenVX is an open, royalty-free standard for cross-platform acceleration of computer-vision applications. It enables performance- and power-optimised computer-vision processing, which is especially important in embedded and real-time use-cases such as face, body and gesture tracking, smart video surveillance, advanced driver assistance systems (ADAS), object and scene reconstruction, augmented reality, visual inspection and robotics.
OpenVX is a low-level programming framework domain that enables software developers to efficiently access computer-vision hardware acceleration with both functional and performance portability. It has been designed to support modern hardware architectures, such as mobile and embedded SoCs as well as desktop systems. Many of these systems are parallel and heterogeneous, containing multiple processor types including multi-core CPUs, DSP subsystems, GPUs, dedicated vision computing fabrics as well as hardwired functionality. Additionally, vision system memory hierarchies can often be complex, distributed and not fully coherent.
Developers need a set of high-level tools and standard libraries like OpenCV and OpenVX that work in conjunction with and complement the underlying C/C++ toolchain. OpenCV is an open source computer-vision software library that contains 2500 functions which, when used by a high-level application, can facilitate tasks like object detection and tracking, image stitching, 3D reconstruction and machine learning.
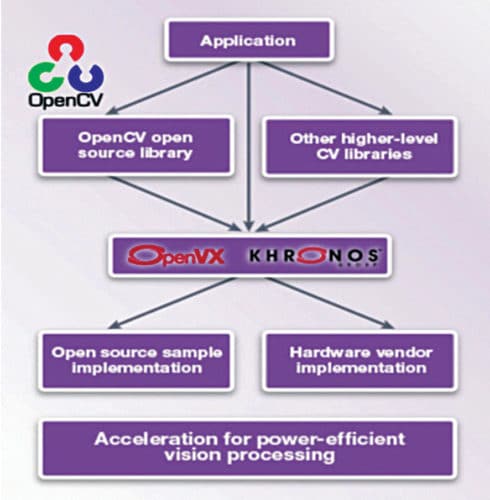
Fig. 8: OpenCV and OpenVX to accelerate vision system development
OpenVX contains a library of predefined and customisable vision functions, a graph-based execution model with task- and data-independent execution, and a set of memory objects that abstract the physical memory. It defines a ‘C’ application programming interface (API) for building, verifying and coordinating graph execution, as well as accessing memory objects.
Graph abstraction enables OpenVX implementers to optimise graph execution for the underlying acceleration architecture. It also defines the vxu utility library, which exposes each OpenVX predefined function as a directly callable ‘C’ function, without the need to first create a graph. Applications built using the vxu library do not benefit from optimisations enabled by graphs; however, the vxu library can be useful, as the simplest way to use OpenVX and as the first step in porting existing vision applications. As the computer-vision domain is still rapidly evolving, OpenVX provides an extensibility mechanism for adding developer-defined functions to the application graph.
AutonomouStuff touts its “completely customisable R&D vehicle platforms used for ADAS, advanced algorithm development and automated driving initiatives.” Conventional ADAS technology can detect some objects, do basic classification, alert the driver of hazardous road conditions and, in some cases, slow or stop the vehicle. This level of ADAS is great for applications like blind spot monitoring, lane-change assistance and forward collision warnings.
NVIDIA DRIVE PX 2 AI car computers take driver assistance to the next level. These take advantage of deep learning and include a software development kit (SDK) for autonomous driving called Drive Works. This SDK gives developers a powerful foundation for building applications that leverage computation-intensive algorithms for object detection, map localisation and path planning. With NVIDIA self-driving car solutions, a vehicle’s ADAS can discern a police car from a taxi, an ambulance from a delivery truck, or a parked car from one that is about to pull out into traffic. It can even extend this capability to identify everything from cyclists on the sidewalk to absent-minded pedestrians.
OpenPilot
OpenPilot project consists of two component parts: onboard firmware and ground control station (GCS). The firmware is written in ‘C,’ whilst ground control station is written in ‘C++’ utilising Qt. This platform is meant for development only.
OpenPilot is basically a behaviour model based on Comma.ai’s trained network. Comma.ai, a startup, used quick hacking of the car’s network bus to simplify having the computer control the car. They did it almost entirely with CNNs. The car feeds images from a camera into the network, and out from the network come commands to adjust the steering and speed to keep a car in its lane. As such, there is very little traditional code in the system, just the neural network and a bit of control logic.
The network is built by training it. As a car is driven around, it learns from the human driving what to do when it sees things in the field of view. Light Detection and Ranging (LIDAR) gives the car an accurate 3D scan of the environment to more absolutely detect the presence of cars and other users of the road. By getting to know during training that there is really something there at these coordinates, the network can learn how to tell the same thing from just the camera images.
When it is time to drive, the network does not get the LIDAR data, however, it does produce outputs of where it thinks the other cars are, allowing developers to test how well it is seeing things. This allows development of a credible autopilot, but, at the same time, developers have minimal information about how it works, and can never truly understand why it is making the decisions it does. If it makes an error, they will generally not know why it made the error, though they can give it more training data until it no longer makes the error.
Developing an autonomous car requires a lot of training data. To drive using vision, developers need to segment 2D images from cameras into independent objects to create a 3D map of the scene. Other than using parallax, relative motion and two cameras to do that, autonomous cars also need to see patterns in the shapes to classify them when they see them from every distance and angle, and in every lighting condition. That’s been one of the big challenges for vision-you must understand things in sunlight, in diffuse light, in night-time (when illuminated by headlights, for example) when the sun is pointed directly into the camera when complex objects like trees are casting moving shadows on the desired objects and so on. You must be able to identify pavement marking, lane marking, shoulders, debris, other road users, etc in all these situations and you must do it so well that you make a mistake perhaps only once every million miles. A million miles is around 2.7 billion frames of video.
Autonomous driving startups
The goal is to build a hardware and software kit powered by artificial intelligence for carmakers. Drive.ai, an AI software startup with expertise in robotics and deep learning, applies machine learning to both driving and human interaction.
Startup FiveAI develops a host of technologies including sensor fusion, computer vision combined with a deep neural network, policy-based behavioural modelling and motion planning. The goal is to design solutions for a Level 5 autonomous vehicle that is safe in complex urban environments.
Nauto offers an AI-powered dual-camera unit that learns from drivers and the road. Using real-time sensors and visual data, it focuses on insight, guidance and real-time feedback for its clients, helping fleet managers detect and understand causes of accidents and reduce false liability claims. The system also helps cities with better traffic control and street design to eliminate fatal accidents.
Oxbotica specialises in mobile autonomy, navigation, perception and research into autonomous robotics. It has been engaged in the development of self-driving features for some time and purports to train their algorithms using AI for complex urban environments by directly mapping sensor data against the actual driving behaviour. Thus far, it has developed an autonomous control system called ‘Selenium,’ which is basically a vehicle agnostic operating system applicable to anything from forklifts and cargo pods to vehicles. It also offers a cloud-based fleet management system to schedule and coordinates a fleet of autonomous vehicles, enabling smartphone booking, route optimisation and data exchange between vehicles without human intervention.
SoCs optimised for neural networks
Chip vendors are using everything from CPUs and GPUs to FPGAs and DSPs to enable CNN on vision SoCs. Currently, CNN-based architectures are mainly mapped on CPU/GPU architectures, which are not suitable for low-power and low-cost embedded products. But this is changing with new embedded vision processors introduced into the market. These vision processors implement CNN on a dedicated programmable multicore engine that is optimised for efficient execution of convolutions and the associated data movement. Such an engine is organised to optimise data flow and performance, using a systolic array of cores called processing elements (PEs). One PE passes its results directly to the other using FIFO buffers, without storing and loading the data to the main memory first, which effectively eliminates shared memory bottlenecks.
Vision processors offer flexibility on how PEs are interconnected, allowing designers to easily create different application-specific processing chains by altering the number and interconnection of cores used to process each CNN stage or layer. This new class of embedded vision processor is not restricted to just object detection with CNN. Other algorithms like a histogram of oriented gradients, Viola-Jones and SIRF can be implemented as well, giving designers the flexibility to tailor the processor to their application.
In parallel processing, an image to which certain parameters are applied produces another image, and as another filter is applied to the image, it produces another image. But the good news is that there are tricks to simplify the process and remove unwanted connections.
The challenge, however, remains in handling a number of different nodes in CNNs, as developers can’t predetermine which node needs to be connected to another node. That’s why they need a programmable architecture and can’t hardwire the connections. Rather than designing a different SoC architecture or optimising it every time new algorithms pop up, a CNN processor only needs a fairly simple algorithm that comes with fewer variables.
