



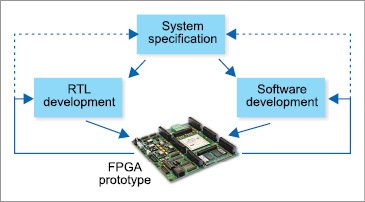
Field programmable gate array (FPGA) prototyping, commonly referred to as FPGA based prototyping, application-specific integrated circuit (ASIC) prototyping or system on chip (SoC) prototyping, is the method to prototype SoC and ASIC designs on FPGAs for hardware verification and early software development.
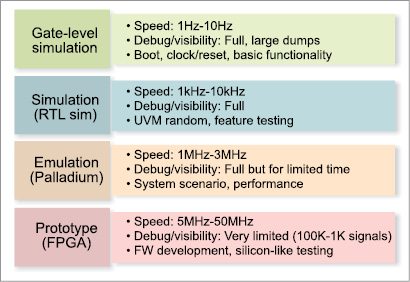
FPGA is a much faster engine for running the register transfer level (RTL) model. Running an SoC design on an FPGA prototype is a reliable way to ensure that it is functionally correct. About a third of all current SoC designs are fault-free during their first silicon pass, with nearly half of all re-spins caused by functional logic errors. FPGA based prototyping allows speed ranges into tens of MHz and often offers the best cost-per-gate per MHz for software development and hardware regressions in the project phase when RTL becomes stable enough, so that fast turnaround time and hardware debug matter less.
A single prototyping platform can provide verification for hardware, firmware and application software design functionality before the first silicon pastime-to-market (TTM) period is shrinking. It is typically limited in capacity and can take months to bring up due to modifications required in the design and subsequent verification. The benefit, once brought up, is a speed range in tens of MHz range that is sufficient for software development.

In today’s technological-driven society, new products are introduced rapidly, and failing to have a product ready at a given market window can cost a company a considerable amount of revenue. If a product is released too late, the product could be rendered useless, costing the company its investment capital for the product.
After the design process, FPGAs are ready for production, while standard-cell ASICs take more than six months to reach production. Today, state-of-the-art ASIC prototyping and software development tools join software development platforms running reference designs with pre-packaged IP configurations. Prototyping kits are operational out-of-the-box, and allow hardware and software developers to immediately engage in integration and validation tasks necessary to ship the next great SoC design.

With the increasing cost of mask sets and continuous decrease of IC size, minimising the number of re-spins is vital to the development process. Single FPGA devices can hold up to 20 million ASIC gates, with utilisation rates of 60 per cent and FPGA systems promise to hold almost 100 MGs. Earlier, the most common hardware configuration on the FPGA prototyping board consisted between four to nine clocks, with the fastest clock running more than 200MHz.
Key advantages and issues
Prototyping is important because of high performance and accuracy, real-time dataflow and extended RTL testing and debugging. FPGA based prototypes offer unbeatable flexibility, capacity and speed. The key advantage of FPGA based systems is speed and the main volume of FPGA based prototypes today is to enable software development and sub-system validation. Many benefits come from the co-design of prototype hardware, firmware and software elements that help expedite migration from raw ASIC RTL and IP.
From a chip perspective, at about 60 per cent into a project, three main issues have to be resolved. First, error rate in the hardware has to be low enough that design teams find confidence to commit to a tape out.
Second, the chip has to be validated enough within its environment so that it works within the system.
The last is that, significant portions of the software have to be brought up to be confident that software/hardware interactions work correctly.
Abstraction levels
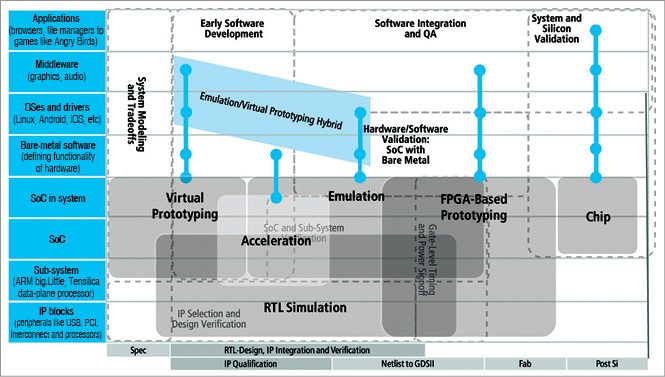
Prototyping today happens at two abstraction levels, namely, using transaction-level models (TLMs) and register transfer level (RTL) models, using five basic engines.
1. Virtual prototyping based on TLM models
2. RTL simulation
3. Emulation
4. FPGA based prototyping
5. Bringing up
FPGA basic engines
FPGA based emulators are typically weaker with respect to debug efficiency and turnaround time, making these less reactive and similar to FPGA based prototypes. The downside to standard FPGA based prototyping is capacity limitations as well as longer bring-up due to the changes that have to be made to map the RTL to the FPGAs. So only the efficient combination of the four engines, namely, emulation, virtual prototyping, RTL simulation and FPGA based prototyping, provides a complete solution.
Emulation. Emulation extends verification to the full chip and at the chip-in-system level by enabling connections to real system environments like PCI, USB and Ethernet. The main advantage of processor based emulation is fast turnaround time for bring-up, which makes it ideal for the project phase in which RTL is not quite mature yet.
In addition, it allows multi-user access and excellent hardware debug insight in the context of real software that can be executed at MHz speeds, resulting in very efficient hardware/software debug cycles. Standard software debuggers can be attached using JTAG adaptors or virtual connections.
Virtual prototyping. Virtual prototyping can enable software development as early as a fortnight after the specification is available. It does not allow detailed hardware debug, which is the initial strength of RTL simulation. Used initially for RTL development, IP integration and design verification, RTL simulation can extend to the complexity of sub-systems and is a sign-off criterion for gate-level simulation and timing sign-off. It allows the fastest turnaround time for new RTLs, offers excellent hardware debug but is typically too slow to execute substantial amounts of software. To better extend to sub-systems and the full SoC, verification acceleration moves the device under test into hardware and can allow enough speed up for bare-metal software development.
The different engine sweet spots as an overlay on the main user tasks are shown in Fig. 3.
Techniques
 Emulation and RTL simulation are combined to achieve simulation acceleration. Emulation and TLMs with fast models from ARM are combined to accelerate operating system (OS) bring-up and software-driven testing. Emulation and FPGA based prototyping are combined to combine the speed of bring-up for new portions of the design in emulation with the speed of execution for stable portions of the design in FPGA based prototyping.
Emulation and RTL simulation are combined to achieve simulation acceleration. Emulation and TLMs with fast models from ARM are combined to accelerate operating system (OS) bring-up and software-driven testing. Emulation and FPGA based prototyping are combined to combine the speed of bring-up for new portions of the design in emulation with the speed of execution for stable portions of the design in FPGA based prototyping.
Hardware assisted verification
Starting at RTL level, the ultimate goal is to make the model execute faster than it could in a software simulator. Another issue is that, software simulation slows down significantly when it exceeds the physical memory of the computer, so there is a capacity issue that plays here as well.
There are two general ways to solve the problem, referred to as direct and indirect implementations.
In the case of direct implementation, while compiling a model into an FPGA, an actual implementation of that model in hardware is created. It may not be the same as the one used in an SoC but it is an implementation nonetheless. Mapping emulates the function of the intended hardware. This technique is generally referred to as emulators, because these are directly executing an implementation of the model.
In indirect implementation, mechanisms are devised that allow effects of concurrency to be evaluated even though the simulator is actually incapable of doing more than one thing at a time.
Simulation accelerators contain a large number of simple processors, each of which simulate a small portion of the design and then pass results between themselves. Each of these processors runs slower than the processor on desktop, but the accelerator may possess millions of these smaller processors and the net result is a significantly higher execution performance. These can deal with parallelism directly as all the processors are running in parallel. An example of this type of hardware-assisted solution is Palladium product line from Cadence.
The custom chip could also contain debug circuitry, visibility mechanisms and a host of other capabilities. Each chip is capable of emulating a small piece of design, and larger designs are handled by interconnecting many chips together, again with sophisticated interconnect capabilities. An example of this type of emulator is Veloce from Mentor Graphics.
Another way to implement an emulator is by using off-the-shelf components such as FPGAs. Here, you not only map the design into the FPGA but also implement visibility, debug and other such capabilities into the FPGA. As with the custom chip, multiple FPGAs can be put together to handle arbitrary design sizes. An example of this type of emulator is ZeBu from EVE.
In in-circuit emulation, an emulator or accelerator is connected into a real-world application. Most emulators can only muster a few MHz of clock speed, especially when full visibility is made available. So it is necessary to insert a speed bridge that can handle the difference in execution rates on each side of the bridge. This involves data buffering or manipulation of protocols to artificially slow down the real world to the rate that the emulator can handle.
The next major way these are used is standalone, wherein the entire model fits into the emulator or accelerator, along with a set of stimuli to exercise the model. These can run as fast as the emulator, stopping only when additional stimulus is required or when captured data has to be flushed out of the device.
If the design contains a processor, it is also likely that a version of the processor exists for the emulator. Emulator vendors provide special boards that make many popular processors available. But if parts of the design or testbench cannot be mapped into the emulator, it has to be coupled with a software execution environment. This is called co-simulation, as it inherently involves two simulation engines cooperating to solve the problem. The emulator can now only run as fast as the simulator, or actually even slower because the communication makes it even slower.
A more modern alternative is what is called co-emulation. The primary difference between the two is that communication is raised to the transaction level rather than being at the implementation level.
V.P. Sampath is an active member of IEEE and Institution of Engineers India. He is a regular contributor to national newspapers, IEEE-MAS section and has published international papers on VLSI and networks
