




AI that once needed expensive data center GPUs can now run on common devices. A system can cut costs, speeds up processing, and makes AI more accessible.
Until now, AI services using large language models (LLMs) have mostly depended on data center GPUs. This has made running AI expensive and hard to access. Researchers at KAIST have developed a method that lets AI run on common GPUs, cutting costs and making AI services more accessible.

Professor Dongsu Han’s team from the School of Electrical Engineering created SpecEdge, a technology that lowers LLM infrastructure costs by using consumer-grade GPUs instead of data center hardware.
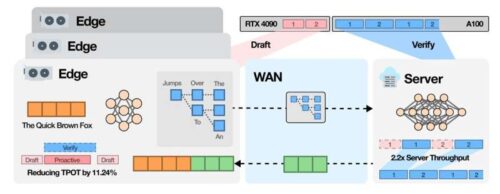
SpecEdge is a system where data center GPUs and edge GPUs found in personal PCs or small servers work together to create an LLM inference infrastructure. Using this approach, the cost per token (the smallest unit of AI-generated text) was reduced by about 67.6% compared to systems that rely only on data center GPUs.
The system uses a method called Speculative Decoding. A small language model running on the edge GPU generates a sequence of tokens quickly. The large-scale language model in the data center then verifies this sequence in batches. Meanwhile, the edge GPU continues generating tokens without waiting for the server, increasing inference speed and infrastructure efficiency.

Compared to performing speculative decoding only on data center GPUs, SpecEdge improves cost efficiency by 1.91 times and server throughput by 2.22 times. It works under standard internet speeds, making it applicable to AI services without specialized network setups.
The server is designed to process verification requests from multiple edge GPUs efficiently, handling more requests without GPU idle time. This design allows data center resources to be used more effectively in serving LLMs.
The research has been recognized at a major AI conference and published as a spotlight paper. The study shows that LLM computations, previously concentrated in data centers, can be distributed to edge devices. This approach lowers infrastructure costs and makes AI services more accessible.
As the system expands to include smartphones, personal computers, and Neural Processing Units (NPUs), AI services are expected to reach more users.
