




The exploding growth of handsets, tablets and the new set of connected devices such as smartwatches, eye-glasses combined with massive, high-bandwidth video usage results in high interference in radio access networks (RANs) and poor spectrum efficiency. Server farms will play an increasing role in future mobile networks but the so-called cloud radio access networks (C-RANs) still face big technical challenges, according to one chip architect working in the area.
In the era of mobile Internet, mobile operators are facing pressure owing to ever-increasing capital expenditures and operating expenses with little growth in income. C-RAN is expected to be a candidate for next-generation access network techniques that can solve operators’ problems. These systems aim to reduce the need to deploy distributed networks of base stations by relying more on central server farms to handle mobile traffic.

C-RAN is a centralised, cloud computing based new RAN architecture that supports 2G, 3G, 4G systems and future wireless communication standards. The name is coined from the four C’s in the main characters of C-RAN system, which are clean, centralised processing, collaborative radio and real-time C-RAN (sometimes also referred to as centralised-RAN). It is the new mobile network architecture for the future mobile network infrastructure, which was first introduced by China Mobile Research Institute in April 2010 in Beijing. It is based on many existing technology advances of wireless communication and optical as well as IT technologies.
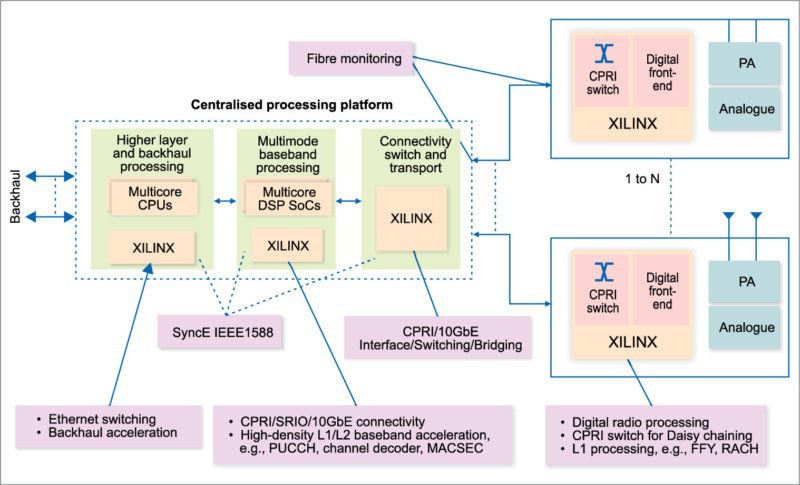
Field-programmable gate arrays (FPGAs) are used in RAN where these shorten time to market and enable high performance, and in L1 hardware acceleration for its fully-virtualised and programmable wireless base station solution, enabling next-generation 4G and 5G interference mitigation and radio access technologies (RAT), C-RAN and cloud self-organising network (C-SON) solutions.
As for networks, carriers will have to run optical fibre links at 20Gbps-40Gbps, or more, between remote antennae and server farms in some cases. For small areas such as auditoriums, 10Gbps Ethernet could be adequate. Solution-providers-proven advanced modem processing unit (MPU) solutions and modem programming language (MPL) for baseband and signal processing as a service (SPaaS) application, combined with Xilinx FPGAs and technologies present a fully-virtualised and programmable base station solution that addresses today’s and future RAN requirements.

The virtual base station (vBS) solution is designed in accordance with ETSI NFV framework, which decouples and virtualises all software and hardware resources including base station L1/PHY software, x86 compute and hardware acceleration (HWA) platform to process real-time, signal processing type of workload. It enables realisation of end-to-end, fully-virtualised networks, from core to edge.
vBS will enable improved network performance, coverage and capacity, and could be deployed in numerous network configurations including C-RAN, traditional macro-cell sites, in-building/outdoor distributed antenna system deployments and even small-cell implementations.
The advent of FPGAs and solutions enables us to support our early customer engagements faster while offering maximum flexibility to address their needs. Emerging vBS requires high performance and programmability, while delivering low cost and power. The software stack runs on baseband unit servers together with an FPGA front-end processing board that emulates baseband signal processing flow.
The FPGA board integrates PCI Express, 10GBps Ethernet, common public radio interface, optical connections and so on, which enables it to bridge telecom and IT datacenter domains. As an accelerator, the FPGA implements many key algorithm units required by baseband signal processing, which increases the system computing power greatly.
RapidIO protocol
Each radio node in the architecture serves a set of users in a small- or macro-cell configuration. In both traditional and distributed architectures, RapidIO protocol connects multiple processing units (for example, DSPs, SOCs, ASICs and FPGAs) in channel or baseband cards. The protocol ensures guaranteed delivery with lowest latency of around 100nsec between any two processing nodes.
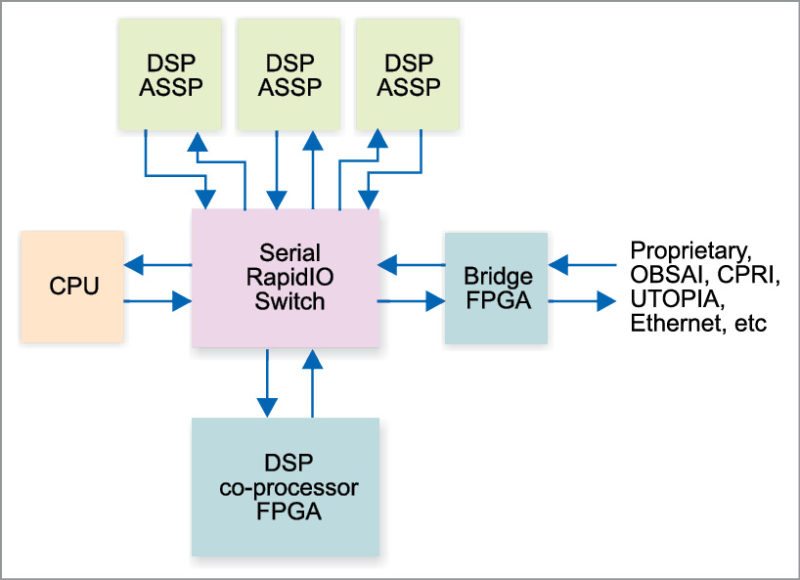
In a typical RAN architecture, once the signal processing related to a particular radio interface is completed, data is transported between the baseband and the radio using CPRI protocol. In a distributed architecture, CPRI protocol may not lead to a cost-effective implementation of load management and interference control, since, by definition, CPRI protocol does not provide a standardised low-latency packet based switching capability that can be used to distribute traffic across multiple baseband cards from radios. RapidIO in this case is expected to provide best-in-class performance.
Two major flows in the access network include transmission from mobile to base station (uplink flow) and reception at mobile from the base station (downlink flow). Retransmission, in the form of hybrid-automatic-repeat-request (HARQ), might be required in case of transmission errors as part of LTE/LTE-A protocol.
HARQ timing of around 4ms is actually much lower than LTE/LTE-A round-trip latency. If the interconnect fabric between processing nodes supports superior flow control and fault-tolerance capability, it is further possible to minimise the number of HARQ retransmissions, resulting into lower latency. This provides a differentiation point for OEMs and eventually leads to better quality of experience for the end user.
To support handover, load balancing and interference management, above major flows further include exchange of information related to handover, channel quality and load indication between various processing units at the base station.
Exchange of information between baseband units should be supported with lowest deterministic latency and guaranteed delivery. This allows demand on the network and interference between various users to be identified without error and in a timely manner. This also enables low-latency handover with reliability as users cross cell boundaries.
To meet the requirements in C-RAN and a small cell, in particular, reliable load management, hand-over and interference management, OEMs are evolving base station designs by taking advantage of RapidIO’s interconnect features and advancements in systems on chip (SoC), memory and radio sub-system components.
For the interconnect, there are two important functions to consider: RapidIO end-point (EP) and RapidIO switching fabric. With integrated EP within SoCs, it is possible to offer lowest latency between applications. With low-latency high-throughput packet based switching protocol, applications can be executed and partitioned across a large number of baseband computing units.
To support lowest latency, it is further possible to co-locate baseband processing units for a large number of small cells in one location. In this case, X2 interface is local to the baseband cluster. Exchange of information with deterministic delivery and lowest latency allows the baseband cluster to control data exchange between the right set of radio units and the baseband units at the right time while minimising or avoiding interference even for users located at cell boundary.
With a cluster of baseband units, it is possible to virtualise and share processing units. This allows average processing capability of computation units to meet the total capacity of a group of cells at any given time, instead of a specific cell all the time.
The technique will be used in big cities, especially in stadiums and subways, which carriers will not want to pack with base stations to handle traffic peaks. C-RANs will also help carriers share the cost of network infrastructure. In some cases, even single antenna will be shared by carriers and will have an IPsec session with data from different carriers in it. Real rollouts are more for 5G networks and define architectural requirements in hardware and software.
One of the biggest challenges is getting servers to handle real-time requirements of physical layer baseband processors. Ideally, some baseband traffic should traverse round-trip paths at milli- or even micro-second speeds. However, time constraints are still fuzzy, because it is more about user experience and the Internet experience.
At first, hybrid designs would let servers handle session- to application-layer jobs, offloading lower-level work to accelerator cards. A classic server works for the control plane but today would not handle transport functions and layer 2 and down very well. In the long term, it will presumably look for ways to integrate server and baseband functions.
Software poses several challenges because carriers will want C-RANs to use their current code. In addition, developers need to figure out how to assign various networking jobs to virtual machines and keep those machines secure. They will also have to find ways to run both general-purpose processor and accelerator codes in virtual machines.
V.P. Sampath is an active member of IEEE and Institution of Engineers India Ltd. He is a regular contributor to national newspapers, IEEE-MAS section, and has published international papers on VLSI and networks
