



Hardware system that eliminates comparators, accelerates nonlinear sorting, and delivers massive gains in speed and energy efficiency—opening new doors for AI, edge computing, and real-time data analytics.
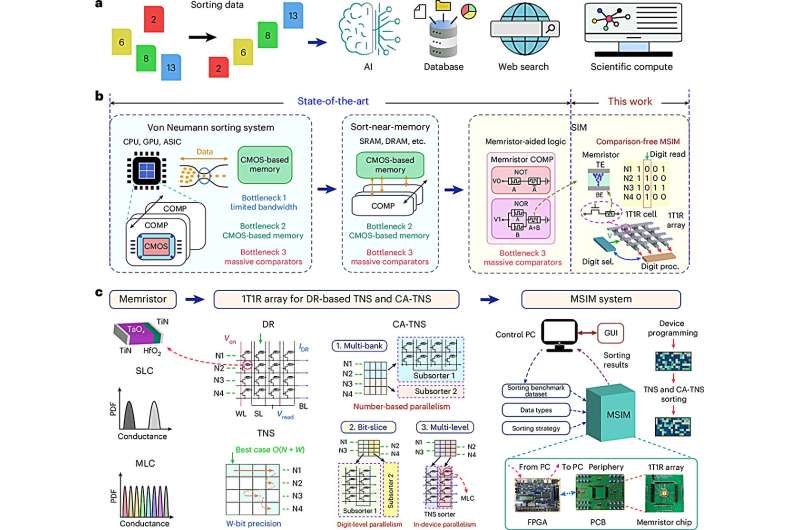
A research team led by Prof. Yang Yuchao from the School of Electronic and Computer Engineering at Peking University Shenzhen has achieved a breakthrough in processing-in-memory (PIM) technology by developing the world’s first sort-in-memory hardware system designed specifically for complex, nonlinear sorting tasks—without relying on traditional comparators. The system introduces a novel architecture built on memristor technology, using a unique Digit Read mechanism to bypass the limitations of conventional compare-select logic. Sorting is a core computational task, but its nonlinear nature has made it difficult to accelerate using traditional PIM methods, which are typically optimized for linear operations like matrix multiplication.

The team tackled this head-on by designing a one-transistor–one-resistor (1T1R) memristor array and coupling it with an innovative Tree Node Skipping (TNS) algorithm that improves computational efficiency by reusing traversal paths and eliminating redundant operations. To scale the system’s performance across diverse data types and sizes, the researchers introduced three Cross-Array TNS (CA-TNS) strategies. The Multi-Bank strategy partitions data across multiple arrays to enable parallel sorting, Bit-Slice distributes bit widths to allow pipelined execution, and Multi-Level leverages the memristor’s multi-conductance states to boost intra-cell parallelism.
These hardware-software co-design innovations result in a high-throughput, reconfigurable, and energy-efficient sorting engine that can adapt to a variety of computational workloads. In benchmark tests, the system demonstrated up to 7.7× faster speed, 160.4× higher energy efficiency, and 32.5× greater area efficiency than leading ASIC-based sorting solutions.The team didn’t stop at simulations—they built a full end-to-end demo using a fabricated memristor chip integrated with FPGA and PCB hardware. In practical applications, the system showed impressive versatility.
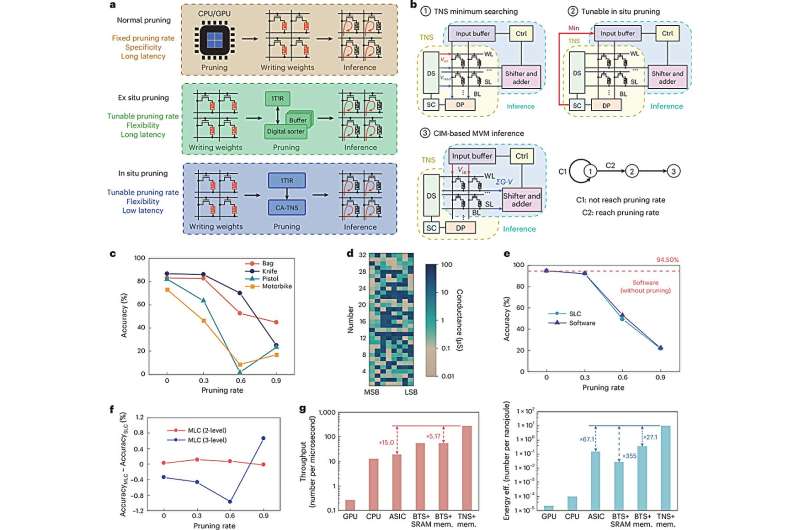
It computed the shortest paths across 16 Beijing Metro stations with low power and latency in Dijkstra’s path planning. In AI inference using the PointNet++ model, it achieved 15× faster performance and 67.1× energy efficiency by enabling tunable sparsity during matrix-vector operations. Prof. Yang’s work redefines the possibilities of PIM architectures and sets a new direction for nonlinear computation acceleration. This flexible and scalable system lays the groundwork for future intelligent hardware in AI, big data analytics, and edge computing.

