




You are moving your shopping cart towards the billing counter. The barcode of each product in your cart has already been automatically transmitted one by one to one of the billing computer systems. This is your first visit to this department store. You are allotted a loyalty card that has a customer ID number and are asked to fill a short form that asks details like your age, gender, income and occupation. A few days later you receive an email from the store informing you about some good offers on headphones; you had purchased an iPod among other things during your last visit. This is data mining at work.
MCI Communications Corp., the long-distance carrier, sifts through almost one trillion bytes of customer phoning data to develop new discount calling plans for its different types of customers. Land’s End, a retail chain, identifies which of its two million odd customers can be sent exclusive mailers on certain specific clothing items that will go well with their existing wardrobe.

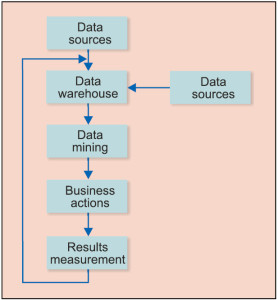

Data warehousing and data mining
Data warehousing is all about capturing data on a periodic basis from various sources and storing it on computers in an organised manner, that is, in virtual warehouses.
Let us take its application in marketing to customers as an illustration. Some common sources of data are details of purchases made at retail outlets, marketing research interviews with customers or simply day-to-day customer transactions (such as amount of money deposited or withdrawn from a bank). Usually, the starting point is a customer database that needs to be elaborate in terms of variables such as demographics like age, family size and income. Customers leave traces of their purchasing behaviour in store scanning data, catalogue purchase records and customer databases.
Customers’ actual purchases reflect their true and actual preferences, and could often be more reliable than answers given during market research surveys. Data mining refers to the analysis of this raw data, which is collected to generate useful and meaningful information, such as finding patterns in terms of products purchased most often and building customer profiles in terms of low, medium and heavy buyers. This information can then be used for business actions like special promotions and loyalty programmes.

A brief history

Data mining was born in the minds of professors and doctorates who used their expertise in statistics to develop algorithms that form the foundation of data mining today. In the initial days, these algorithms were custom-coded using programming languages such as FORTRAN.
Early applications of data mining were more academic in nature. As this work evolved, different vendors fabricated new levels of tooling to make application of these data mining algorithms more user-friendly.
However, even today, data mining remains more of a standalone activity conducted by a dedicated staff, and its terminology is still quite academically-oriented. This has resulted in data mining as being perceived to be mysterious and somewhat aloof from day-to-day IT projects.
When a business problem is encountered, the IT team starts working on it by developing and understandsing data warehouse aspects. The data mining team works differently and contributes by suggesting some kind of analyses or recommendations that will lead to a certain type of action.
Infrastructure requirements
In order to be effective and efficient, the data mining system requires some mandatory inputs. It needs large investments in hardware, software, database, programming communication links and skilled personnel. The volume of data is usually very high in a data mining application. Handling large amounts of data requires software with advanced competencies, and the system needs to be user-friendly and easily accessible by different user departments.
Data warehousing needs to be done carefully as, say, critical marketing actions may be taken based on data analysis. Since data is collected at multiple locations and times, there needs to be a quality control process in place.


Moreover, the database must be continuously updated, as it is a dynamic situation with some old customers leaving, new ones joining and others changing their interests.
Data mining cannot be carried out in isolation. It needs to be integrated with the company’s overall marketing strategy.
Finally, data is nothing but numbers. It has to be made to run around, go places and analysed innovatively in order to get good returns on investment.
Currently, data mining applications are offered for all sizes of systems for mainframe, client/server and PC platforms. System prices range from as low as a few thousand dollars for the smallest applications to as high as a million dollars a terabyte for the largest. Enterprise-wide applications generally range from 10GB to over 10TB.
There are two key technical considerations. First is the size of the database—the larger is the data being processed and maintained, the bigger will be the required system.
Second is query intricacy—the more complex the queries and the larger the number of queries being processed, the more powerful the system required. Relational database storage and management technology is sufficient for most data mining applications less than 50GB. However, this needs to be significantly increased to take on bigger applications.
Some vendors have added widespread indexing capabilities to advance query performance, while others use new hardware architectures such as massively parallel processors (MPPs) to accomplish order-of-magnitude improvements in query time.
Applications
Data mining can be applied to a number of diverse areas and has already proven to be an immensely useful tool.
Law and order. In the last few years there has been a sharp increase in crime rate in India, a country that is as vast as it is diverse. The police have a very challenging role in terms of thinking more intelligently than the criminals and staying ahead of them. One key result area is higher investigative effectiveness and the need for user-friendly interactive data interfaces when looking for clues and verifying records, among other activities.

National Crime Record Bureau (NCRB) maintains a large crime database and uses crime data mining techniques such as clustering. In earlier times, extracting and exchanging information among police agencies was a very time-consuming process and often data was not available in the time of need.
The government of India made use of IT and implemented a government-to-government (G2G) model called crime criminal information system (CCIS). This system is designed to create computerised storage, analysis and retrieval of criminal records. For example, if a person has been robbed of his or her mobile phone, the police can use data mining tools to search the IMEI number on the basis of the mobile phone number and get it blocked.
Healthcare. Healthcare transactions generate a vast amount of data, and this too is multi-faceted and large to be processed and analysed by conventional means. Data mining can advance decision making by discovering patterns and trends in large amounts of complex data.
In healthcare, major application areas include evaluation of treatment effectiveness, management of healthcare, customer relationship management (CRM), and detection of fraud and abuse.
By comparing and contrasting causes, symptoms and courses of treatments, data mining can provide an analysis of the courses of action that can prove to be successful. For example, results of patient groups treated with various drug regimens for the same ailment can be compared to establish which treatment is most effective and offers higher value for money.
Financial applications. Data mining is a very useful tool in this sector, and forecasting stock markets, currency exchange rates, bank bankruptcies, understanding and managing financial risks, trading futures, credit ratings, loan management, bank customer profiling and money-laundering analyses are some core tasks.
Cross-selling refers to selling a range of related products to a single customer profitably, based on certain assumptions. These assumptions are based on understanding products that have synergy with customer profiles and their requirements.

Banks often attempt to cross-sell credit cards, pensions and life insurance policies. Standard Chartered Grindlays Bank faced severe competition from other banks due to poaching, similarity in products and services and other factors. Its business intelligence unit using data analysis and a test-and-learn culture was able to find out the likelihood of customers to take on a new product. For example, it knew which of its card members were more likely to take an auto loan, resulting in more focused marketing campaigns and reduced costs with improved customer satisfaction. As a result, the marketing department was empowered with information to increase cross-holding, target most valuable customers and also help in the next best product strategy for a customer.
It is expected that there will be a high growth of hybrid methods, that is, those that merge diverse models and deliver better performance vis-à-vis individuals in the area of data mining in finance.
In this integrative approach, individual models work like trained artificial experts. Hence, their combinations can be oriented in the same manner as consultation by human experts. Also, these artificial experts can be successfully pooled with human experts. In times to come, these artificial experts will be configured as autonomous intelligent software agents.
Sales and marketing applications. Data mining is used to arrive at a customer’s value, also known as lifetime value (LTV), which is a useful concept in measuring customer retention. Data mining can also be used to predict a customer’s likelihood to switch to competition. Probability scores for each customer can be calculated based on certain given inputs, for example, a churn score of 0.85 can be read as an 85 per cent chance of cancelling service.
Endpoint
While talking about data mining, we cannot ignore the popular buzzword of recent times—Big Data. Big Data slowly came to be differentiated from small data since it was not generated purely by a firm’s internal transaction systems. It was externally sourced as well, coming from the Internet, sensors of different kinds, public data initiatives such as the human genome project, and captures of audio and video recordings.
Imagine this, UPS, the world’s largest courier company, captures information on as many as 16.3 million packages, on average, that it delivers daily, and it receives 39.5 million tracking requests a day. The most recent source of Big Data at UPS is the use of telematics sensors in almost 50,000 company trucks that track parameters such as speed, direction and braking.
It is said that it is almost like there are two eras for organisations: Before Big Data, or BBD, and After Big Data, or ABD.
In BBD era, analysts spent much of their time preparing data for analysis and relatively lesser time on the more important part, that is, the analysis itself. Most business intelligence activity catered to only what had happened in the past and offered no enlightenments or predictions.
The ABD phase began around 2005 when we saw several dotcoms or Internet based and social network firms come up, mainly in the Silicon Valley. These firms such as Google and eBay started gathering and dissecting new type of data.
LinkedIn, for example, today offers several value-added data products such as people you may know, jobs you may be interested in and so on. This is all a result of data mining.
As the Internet penetration increases and customers become more demanding, greater will be the demand on more sophisticated infrastructure, that is, hardware, software and apps.
Also, there will be a need for sharp and smartdata scientists who can slice and dice the data in a number of ways.
We should not forget that companies like Google, LinkedIn, Facebook and Amazon became what they are today not by giving customers mere information but by giving them shortcuts to key decisions and actions that helped make their life better.