



This article, using an example, shows how deep learning mechanism can help solve an artificial intelligence (AI) problem. It gives a good insight on how layers in training data can be formed.
Creating an artificial intelligence (AI) system comes with many challenges and the biggest of all is to see how to get closer to human thinking and solve a problem the way a human will. Human or cognitive level of thinking is the most difficult, and to achieve that, it is necessary to make use of deep learning mechanism. Since convolution neural network (CNN) is the core of the deep learning mechanism, it allows adding desired intelligence to a system.

A neural network has layers of preceptors or logics/algorithms that can be written. Hence, the more layers of this logic one adds, the more the solution gets closer to cognitive thinking. The most important step here is back propagation, which helps analyse whatever has been done in all those layers. It then provides additional help by giving three times more accurate results.
Back propagation
Let us take the classic example of the lift versus staircase. Here, apart from all other aspects, it still depends on the mood of the person—whether the person will consider taking the lift or stairs—and this can change every day.
We create infinite scenarios, yet everyday being a new day we cannot be sure what will the mood be today, and still we will try to solve this and make it as accurate as we can using the following steps.
Human mood capture
How do we capture this mood and decide what is the person’s mood today? We cannot read anyone’s mind, but this can be achieved through face reading, which can give us facial expression and emotions, and body language, which can give us more information on the mood.
Face reading
Face reading or face detection software can help capture the emotions of the face, such as happy face, sad face or other. (There are many different types of emotions that can help in capturing a person’s mood.) In this case, instead of photos, video clips of the person would be more helpful in making accurate predictions of the mood.
Note that, there are hundreds of different emotions and emojis, and if we consider all of them, it will not solve the issue. It would make up huge amounts of similar data, since there are many emotions that are related and similar to each other. Only a few basic emotions need to be checked, which are obvious in nature. It works in the same way as it does with colours, where there are infinite colours, but we take three primary colours and then differentiate them accordingly. Hence, the seven basic emotions to be considered are joy, sad, angry, fear, disgust, neutral and surprise.
According to psychology, facial expressions are checked with eyes, nose and mouth changes. Therefore the facial image should be divided into three equal horizontal parts: forehead till eyes, nose and lips till the chin.
Body language
This is a very important aspect, and there are many things involved in body language. But the main things to consider are walking pace, hand and leg movements, and postures.
For a more accurate analysis, it is important to find the correlation between facial expressions and body language for decision-making.
How to begin
Video clip is captured in the CCTV camera that is near the lift. It is called the unstructured form of data. This must be read by the machine in a different manner. Here comes the magic of deep learning, which is the most suitable technique in decoding any form of complex unstructured data.
How it is decoded
The core of AI is where we extensively use statistical and complex mathematical formulae and concepts like calculus, integration, derivatives, complex numbers and algebra fundamentals to solve this, and get results.
The video clip is broken into continuous shots of images and then every image is read by applying the above mathematical rules. All these rules are defined and calculated in API functions created by Python.
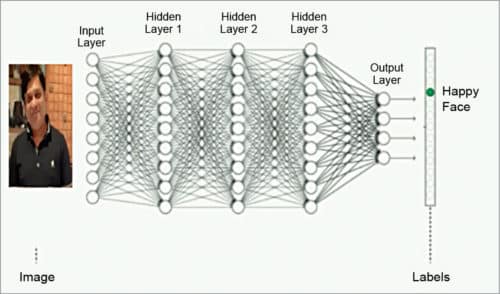
Every image can be divided into number of pixels. In a normal scenario, a coloured image is divided into 32×32 pixels. But since we have to divide the image in three parts, let us set the pixels as a round figure to make calculations simple for this scenario. Let us make the image in 30×30 pixels, so we get total 900 pixels for the image.
Now, we have the following ways an image is divided:
- Every image is divided into three equal horizontal parts based on facial expressions, as explained earlier. This way we have 300 pixels for each part of the image.
- Every image is a coloured image; thus, it is divided into three red, green and blue (RGB) images. Here, every colour will have 900 pixels. Thus, the total for three primary colours will be 2700 pixels.
This way we break down every image into 900 instances of weight, which forms the first layer in the deep learning mechanism.
Considering different formulae and calculations, we will keep adding different layers, and the last layer (output layer) will contain the total number of emotions captured and output using the deep learning mechanism—in this case, output will be seven emotions.
Let us divide the image in three parts and analyse each part separately. All three parts will enter the first layer together but will be weighted separately. So, we will have the following in the first layer:
First layer preceptor
This is divided into a square and very small pixels; in our case, 30×10 pixels (one third of the image is taken). The higher the number of pixels, the more accurate the results. Every pixel, depending on darkness, will give numbers ranging from 0.0 to 1.0. These are called weights of every pixel.
Similarly, the other two images will also be weighed.
Second layer preceptor
All pixel numbers will be captured and given to the second layer.
This will capture every single pixel based on the higher or lower number, and finally the figure will be read. Here we can capture lines formed near the eyes. Based on the lines and shape of the eyes captured we can decide the emotion.
It is the same for the other two images.
Now we get three different weights of eyes, nose and lips, which will help us come to some conclusion.
Drop-out layer
When we have created five to six layers, and we come across some layer that shows too much learning or very little learning, both of which are not so useful in machine learning and deep learning, then that layer must be dropped out of the structure. But this must be done after proper analysis and understanding, and it depends completely on the data scientist and the situation to decide which layer must be dropped.
Back propagation analysis
This figure can be compared with back propagation of different emojis that we have. This analysis is done when we get some wrong result at the training stage. If we show a happy face and its giving output as sad face, then we have to do back propagation and find the source of the issue, and then solve it.
In our case, there will be an output of seven different emojis, and in the training data, we give all seven images for the machine to learn. This step is sort of reverse engineering, where we go back from the final layer to the previous layer to check if there are any mistakes.
Once that is resolved, we can move ahead with test data, which will be the actual image that will be used for machine learning to figure out the emotion. If we do this correctly, with hundred per cent results, then in test data we should get around 95 per cent correct result.
If this is successful, we have a ready machine learning mechanism for facial expressions and face reading software. This will help us analyse the face expressions and decide if these are happy or sad ones.
Kanu Ratan Butani is working as project manager in a software company in Mumbai. He has fifteen years of experience in Java, EAI and AI-related technologies.
