




The concept of tapping unused CPU cycles was born in the early 1970s. This was the time when computers were first getting linked together using network engineering. In 1973, Xerox’s Palo Alto Research Center (PARC) installed the first Ethernet network, and the first full-fledged distributed computing effort was underway. Scientists John F. Shoch and Jon A. Hupp developed a worm (as they named it) and imagined it moving from machine to machine using idle resources for doing something resourceful. Richard Crandall, an eminent scientist at Apple, started putting idle, networked NeXT computers to work. He installed software that enabled the machines to perform computations and to combine efforts with other machines on the network, when not in use.
The term grid computing came up much later in early 1990s as a metaphor for making computer power as easy to access as an electric power grid. CPU scavenging and volunteer computing became quite popular in 1997 courtesy distributed.net. Two years later, SETI home project was established to tap the power of networked PCs worldwide, with the objective of solving CPU-intensive research problems.

Ian Foster, Carl Kesselman and Steve Tuecke are widely regarded as the fathers of the grid, as they brought together the ideas of the grid (including those from distributed computing, object-oriented programming and Web services).

They pioneered the creation of Globus toolkit that incorporates not only computation management but also storage management, security provisioning, data movement, monitoring and a toolkit. This was used for developing additional services based on the same infrastructure, including agreement negotiation, notification mechanisms, trigger services and information aggregation.
Globus Toolkit remains the de facto standard for building grid solutions. In 2007, the term Cloud computing became a buzz word and is conceptually similar to the canonical foster definition of grid computing.
What grid computing is all about
Grid computing is a type of distributed computing that comprises coordinating and sharing computing, application, data, storage or network resources across dynamic and geographically spread out firms. Basically, it is a computer network in which each computer’s resources are shared with every other computer in the system, that is, processing power, memory and data storage are all unrestricted resources that authorised users can access and control for certain projects.
A grid computing system can be elementary and homogenous such as a pool of similar computers running on the same operating system (OS), or complex and heterogeneous such as inter-networked systems consisting of nearly every computer platform that exists.
Grid computing started as a response to scientific users’ need to combine huge amounts of computing power to run very complex applications. The ad hoc assemblages of distributed resources were coordinated by software that mediated the various OSes and managed aspects like scheduling and security to create sophisticated, virtual computers.
Grid computing remains confined more to the research community and is a sign of utility-style data processing services made feasible by the Internet. Peer-to-peer computing that enables unrelated users to dedicate portions of their computers to cooperative processing via the Internet is a related phenomenon used mostly by consumers and businesses. This harnesses a potentially large quantity of computing power in the form of excess, spare or dedicated system resources from the complete range of computers spread out across the Internet.
Grid-related technologies can change the way organisations deal with multifaceted computational problems. Many grids are constructed by using clusters or traditional parallel systems as their nodes. For example, World Wide Grid, used in evaluating Gridbus technologies and applications, has many nodes that are clusters.
Cluster computing is made up of multiple interconnected and independent nodes that cooperatively work together as a single unified resource and, unlike grids, cluster resources are owned by a single organisation, and are managed by a centralised resource management and scheduling system that manages allocation of resources to application jobs.
Organisations that are computational power dependent to further their business objectives often have to drop or scale back new projects, design ideas or innovations, simply due to lack of computational bandwidth. Frequently, project demand exceeds computational power supply, despite considerable investments in dedicated computing resources. Upgrading and purchasing new hardware is an expensive option and could soon run into obsolescence, given the rapidly-changing technology.
Grid computing is a better solution given the better utilisation and distribution of available IT resources. It can be used in executing science, engineering, industrial and commercial applications such as data mining, financial modelling, drug designing, automobile designing, crash simulation, aerospace modelling, high-energy physics, astrophysics, Earth modelling and so on.
Applications of grid computing
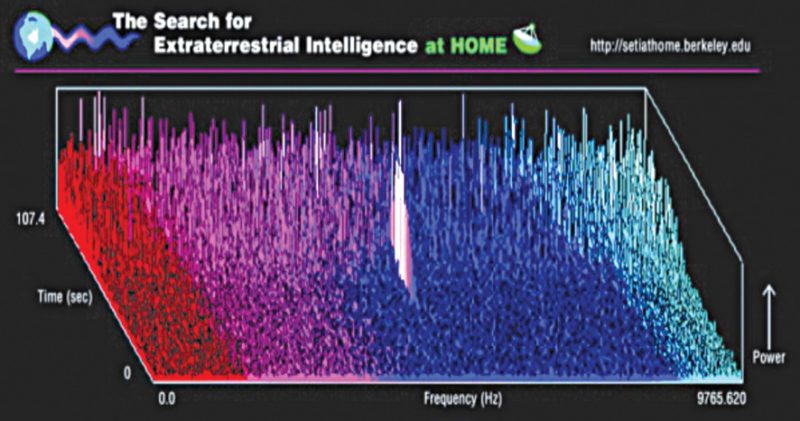
SETI@home project. University of California at Berkeley, USA, coordinates one popular scientific example of grid computing, which is an Internet community application that uses background or downtime resources from thousands of systems, many of these home desktops, to analyse telescope data for the search for extraterrestrial intelligence (SETI) project.

The project’s focus is to search for radio signal fluctuations that may indicate a sign of intelligent life from Space. SETI @home is one of the largest and most successful of all Internet-distributed computing projects. Launched in May 1999 to sift through signals collated by Arecibo Radio Telescope in Puerto Rico (the world’s biggest radio telescope), the project originally received far more terabytes of data on a daily basis than its assigned computers could handle. Therefore the project directors looked up to volunteers, inviting individuals to download SETI@home software to spare idle processing time on their computers for the project.
After posting a backlog of data, SETI @home volunteers began processing present segments of radio signals captured by the telescope. Currently, about 40GB of data is downloaded every day by the telescope and transmitted to computers all over the globe, to be analysed. Results are sent back via the Internet, and the program then collects a fresh segment of radio signals for the PC to process.
More than two million people—the largest number of volunteers for any Internet-distributed computing project—till date have installed SETI@home software. This global network of three million computers averages about 14 TeraFLOPS, or 14 trillion floating point operations per second, and has gathered more than 500,000 years of processing time in the last two years. Using traditional methods to achieve similar throughput would have meant an investment of millions of dollars and perhaps more than one supercomputer.
Folding@home project. This project is somewhat similar to SETI@home project and is administered by Pande Group, a nonprofit institution in Stanford University’s chemistry department. It involves studying proteins. The research includes the way proteins take certain shapes, called folds, and how that relates to what proteins do. Scientists believe that protein misfolding could be the cause of diseases like Parkinson’s or Alzheimer’s.
Hence, there is a possibility that by studying proteins, Pande Group may unearth novel ways to treat or even cure such diseases.
World Community Grid (WCG) project. This project is an initiative to create the world’s largest public computing grid to process scientific research projects that benefit humanity. It was launched in November 2004 and is coordinated by IBM with client software available for Windows, Linux, Mac OS X and Android OSes.
In 2003, IBM and other research participants sponsored Smallpox Research Grid Project to fast-track the discovery of a cure for smallpox. The study used a huge distributed computing grid to analyse compounds’ effectiveness against smallpox. The project enabled scientists to observe and filter 35 million potential drug molecules against several smallpox proteins to shortlist good candidates for developing into smallpox treatments.
In the first 72 hours, 100,000 results were returned. By the end of the project, 44 strong treatment candidates were identified. Based on the success of the smallpox study, IBM announced the birth of WCG with the objective of creating a technical environment where other humanitarian research could thrive.
In the beginning WCG only supported Windows, using the proprietary Grid MP software from United Devices, which powered grid.org distributed computing projects. Popularity for Linux support led to the addition in November 2005 of open source BOINC grid technology, which powers projects such as SETI@home and Climateprediction. In 2007, WCG migrated from Grid MP to BOINC for all of its supported platforms.
The project uses idle time of Internet-connected computers around the world to perform research calculations and analyse aspects of the human genome, HIV, dengue, muscular dystrophy, cancer, influenza, Ebola, virtual screening, rice crop yields and clean energy. Users install WCG client software onto their computers. The software quietly works in the background, using spare system resources to process work for WCG.
When a task or work unit is completed, the client software sends it back to WCG over the Internet and downloads a new work unit. To ensure accuracy, WCG servers send out multiple copies of each work unit. Thereafter, on receipt of results, these are collected and validated against each other.
Applicants can select the graphics output by the current work unit as a screensaver. Public computing grids such as SETI@home and Folding@home are dedicated to a single project, while WCG caters to multiple humanitarian projects under a single banner. Users are included in a sub-set of projects by default, but can opt out of projects when they want. By October 2014, the organisation had partnered with as many as 466 other companies and organisations to aid in its work, and had more than 60,000 active registered applicants.
Putting yourself on the grid computing map
Today, there are a number of such active grid computing projects. However, several of these projects are not on a continuous basis, that is, once the respective objectives are achieved, the projects disintegrate. In some instances, a new, related project can take over the task of a completed one.
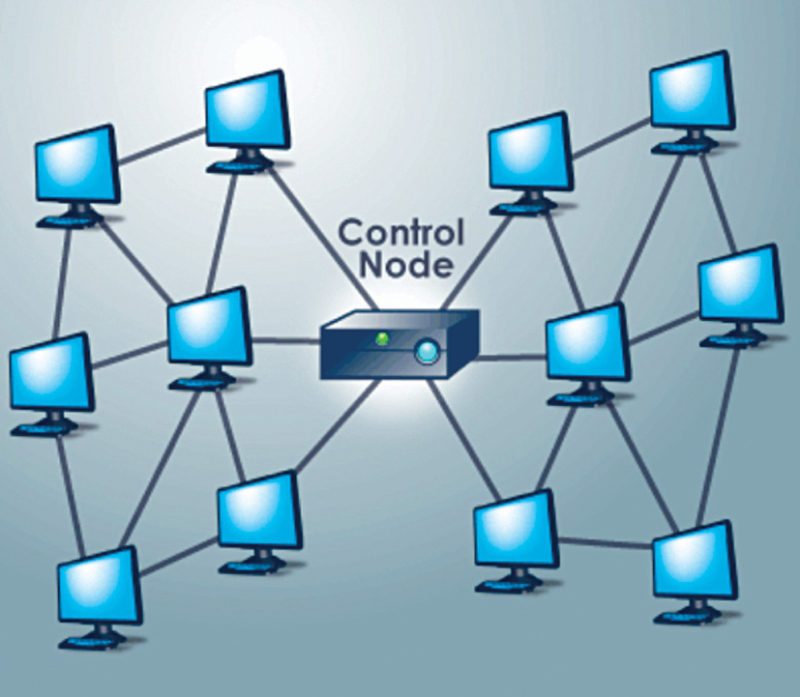
Each of these projects has its own special features but the process of participation is almost the same. A person interested in becoming a user downloads an application from the project website. After installation, the application contacts the respective project’s control node, which then transmits a piece of data to the user’s computer for analysis. The software analyses the data, driven by unutilised CPU resources.

It is very likely that the PC that you are using is not utilising the total computing power at a given time. Even when you are engaged in a game, creating graphics or surfing the Web, you may only be employing a fraction of your machine’s available computing power.
The project’s software generally has a very low resource priority; if the user needs to activate a program that needs a large amount of processing power, the project software switches off temporarily. Once CPU usage returns to normal, the software begins analysing data again. Ultimately, the user’s computer finishes the data analysis asked for.
At that time, the project software sends data back to the control node, which relays it to the relevant database. Then, the control node sends a new set of data to the user’s computer, and the cycle replicates itself. If the project garners sufficient applicants, it can meet ambitious goals in a relatively short span of time.
Privacy and security aspects. Most grid computing firms provide an assurance that the applicant’s privacy will not be overrun in any way. The software is allowed to only update project-specific data in its own files. Of course, members always have the option of opting out of a project, at any point of time. Applicants can generally decide what level of their system resources they would like the grid computing company to use. They can also give their preferences in terms of whether the program runs as a screensaver or an application, when computation and communication can be done, whether connections should be made automatically and which proxies and firewall settings to use and so on.
To safeguard member privacy, members are made to create a member name when they install an agent. This name is stored in the member profile directory and used to identify each member on the company website and on any scoreboards.
Endpoint
For grid to enter the technology mainstream, it will need to move beyond computer-intensive applications that are parallel in nature, to transactional applications like online banking and typical business functions.
The way applications are developed will also have to evolve for the grid to gain greater approval. Grid computing is being talked of as the next big thing for corporate computing, and it can enable companies to make more optimal use of their IT.
The biggest advantage of grid computing for users is that they can run multiple applications without modification, rather than having to rely on dedicated computer clusters in the datacenter. A user’s application will request a Web service, and some computer on the grid will respond.
The grid could also be used in cities to provide applications with higher flexibility, as there would be no single point of failure. Grid computing could become the most preferred method for users to access the database. However, one issue yet to be resolved is licensing, as there is no way the model for licensing today can support on-demand computing.
As grid computing systems’ complexity increases, it is likely to result in more organisations and corporations developing multipurpose networks. We can even look forward to a time when corporations inter-network with other companies. In that environment, computational problems that seemed impossible may be condensed to a project that has the duration of a few hours. Let us wait and watch!
Deepak Halan is associate professor at School of Management Sciences, Apeejay Stya University

